
物理学家以欣赏简化模型而闻名,甚至可能过于简化(Devine 和 Cohen,1992)。生命系统的复杂性与这种简化的驱动力明显存在矛盾;我们或许可以同情那些担心我们的理论冲动可能与生命丰富的分子细节不匹配的生物学家。一种有用的回应是,生物学并没有什么特别之处:在凝聚态物理学和统计力学中,我们经常使用比底层微观机制简单得多的模型来描述材料的宏观行为。这些简化模型之所以成功,不是因为我们幸运,而是因为重整化群(Wilson,1979,1983)。
重整化群(RG)的核心思想是,当我们改变观察系统的尺度时,我们对系统的描述如何系统地变化。一个关键的定性结果是,随着我们 "放大" 以观察更长的长度尺度,许多不同的微观机制会趋向于相同的宏观行为。这意味着,如果我们能够将大规模现象归类到正确的普适类中,即使我们无法正确处理所有小规模细节,我们也可以定量地理解大规模现象,这赋予了我们编写复杂系统相对简单模型的许可(Anderson,1984)。我们希望在大脑的背景下行使这种许可。为此,我们需要了解如何在缺少许多通常指导(局部性、对称性等)的情况下实现 RG。然后我们可以问,当我们从单个神经元放大到更粗粒化的变量时,数据中是否有任何迹象表明简化出现了。
Taking inspiration from the RG
重整化群的发展是二十世纪下半叶理论物理学的伟大篇章之一,其起源在于理解物质在短距离和长距离上的行为(Gell-Mann 和 Low,1954;Kadanoff,1966)。这些思想在1970年代初期得以结晶,并在彻底改变我们对基本粒子之间强相互作用、二阶相变的临界现象、向混沌的过渡等方面的理解中发挥了核心作用(Wilson,1983)。这些思想如何帮助我们思考神经元网络?
在统计物理学的 RG 的标准表述中,我们从一组定义在某个微观长度尺度 $l_{0}$ 上的变量 $z_{l_{0}}\equiv \{z_{i}(l_{0})\}$ 开始。这些变量的描述由一个哈密顿量给出,该哈密顿量反过来指定了玻尔兹曼分布 $P_{l_{0}}(z)$,或者我们可能会对该哈密顿量生成的动力学感兴趣。然后我们想象 "粗粒化" 这些变量,以平均掉某个 $l > l_{0}$ 以下长度尺度的细节。结果是一组新的变量 $z_{l}$,我们可以询问支配这些变量的等效哈密顿量。如果我们认为哈密顿量是由不同类型的相互作用构建的,那么当我们将尺度从 $l_{0}$ 改变到 $l$ 时,这些相互作用的有效强度发生了变化,这就很自然地说,RG 引导我们在改变 $l$ 时跟踪这种流动。尽管这种相互作用强度的流动或耦合常数的运行通常是 RG 分析的目标,但 Jona-Lasinio(1975)早期强调,我们可以更一般地考虑概率分布 $P_{l}(z)$ 空间中的流动,而不参考任何哈密顿量。
重整化群的一个基本结果是,随着 $l$ 变大,许多不同的起始分布 $P_{l_{0}}(z)$ 会收敛到相同的 $P_{l}(z)$。在这条轨迹上,分布的参数表现出作为 $l$ 函数的简单缩放行为。一个熟悉的例子是中心极限定理,如果 $P_{l_{0}}(z)$ 中的变量相关性足够弱,那么当 $l$ 变大时,$P_{l}(z)$ 会趋近于高斯分布,在此过程中,单个变量的方差按 $1/l$ 缩放。RG 预测,更有趣的起点可以流向稳定的非高斯分布,其矩按 $l$ 的非平凡幂缩放。
重整化群方法提供了一个框架,帮助我们理解如何从晶格上的离散 Ising 自旋转变为平滑变化的局部磁化描述,或者从单个分子的位移和动量转变为流体的密度及其流动速度。在这些例子中,粗粒化操作是由对称性和局部性指导的。在生物学背景下,RG 思想最成功的发展可能是对于鸟群和昆虫群体,在那里对称性和局部性的思想仍然有用(§A.2)。对于神经元网络,连接可以跨越包含数千个细胞的距离,局部性原则不再是指导,并且没有明显的对称性。那么,我们如何选择粗粒化策略呢?
也许从重整化群中获得灵感的一个更严重的问题是,RG 被表述为一种理解理论或模型的方法,驯服多尺度自由度之间相互作用的复杂性。这些理论当然对实验做出了定量预测,但在没有明确定义模型的情况下,不清楚如何继续。最近开始对适度真实的尖峰神经元网络模型进行重整化群分析(Brinkman,2023),我们希望会有更多这样的工作。但保持到目前为止讨论的精神,我们想问:我们如何使用 RG 来指导对大量真实神经元群体的新兴数据的分析?
为了解决这些挑战,我们依赖两个关键思想。首先,如上所述,关于神经元网络电活动的现代实验使我们能够访问类似于统计物理模型上 Monte Carlo 模拟轨迹的东西,尽管这是一个我们不知道如何写下的模型。因此,我们可以遵循现在经典的此类模拟分析方法,例如 Binder(1981):我们从最微观尺度的原始数据开始,构建粗粒化变量,并随着粗粒化尺度的变化,跟踪这些变量分布的各种特征。
其次,在缺乏局部性的情况下,我们将使用 测量的成对相关性 作为指导,确定哪些神经元是 "邻居" (Bradde 和 Bialek,2017)。在一种版本中(§VII.B),这涉及将最相关的细胞的活动平均在一起,构建类似于块自旋的神经元簇(Kadanoff,1966)。在另一种版本中(§VII.C),我们连续滤除对整体方差贡献较小的人口活动的线性组合,这类似于动量壳构造(Wilson,1983)。我们将看到,这两种方法都揭示了简单、精确且可重复的缩放行为,这些行为现在已在多个有机体的多个大脑区域得到确认。然后我们讨论这些结果的意义和一些未来的方向 §VII.D。
By analogy with real–space methods
重整化群方法在统计物理学中基于粗粒化的概念,即平均微观细节。如果我们从存在于常规晶格上的变量 $\{z_{i}\}$ 开始,那么通过将变量与其近邻结合起来进行粗粒化是很自然的,如图 32 所示。形式上我们可以写成
$$ z_{i}\rightarrow \widetilde{z}_{i} = f\left(\sum_{j\in\mathcal{N}_{i}}z_{j}\right) $$
其中 $\mathcal{N}_{i}$ 是围绕结点 $i$ 的邻域。如果函数 $f(\cdot)$ 是线性的,那么我们只是对一个邻域进行平均,例如,如果我们迭代,这将导致从离散的类 Ising 变量到更连续的局部磁化。如果 $f(\cdot)$ 是一个阈值函数,那么我们可以实现"大多数规则",这样类 Ising 变量集群就被映射到更稀疏晶格上的类似 Ising 的变量,就像原始的块自旋构造(Kadanoff,1966)一样。
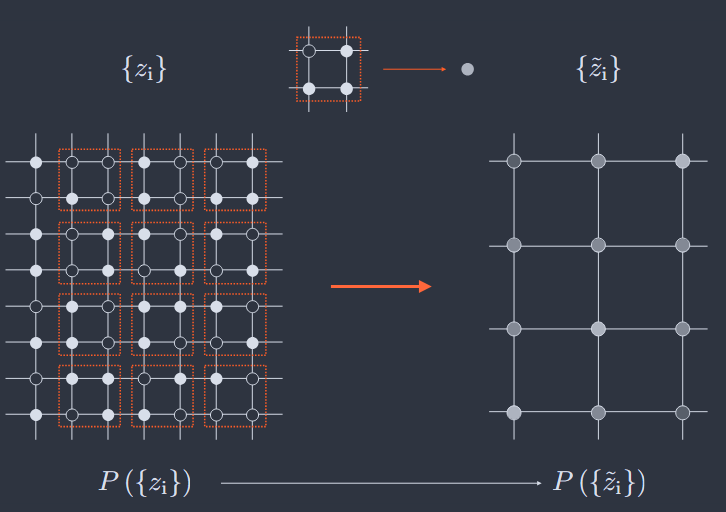
在常规晶格上的粗粒化。我们从二值(黑/白)变量 $\{z_{i}\}$ 开始,并用这些变量的平均值 $\{\widetilde{z}_{i}\}$ 替换 $2 \times 2$ 块,如灰度所示。有趣的问题是,当我们进行粗粒化(不仅仅是一次,而是迭代)时,联合分布会发生什么变化。
在具有局部相互作用的系统中,邻域内的变量通常彼此之间相关性最强。这表明,即使我们没有邻域的概念,我们也可以通过搜索最相关的变量并使用它们来构建我们在粗粒化中使用的集群来取得进展。图 33 显示了这如何适用于神经活动的示意图。
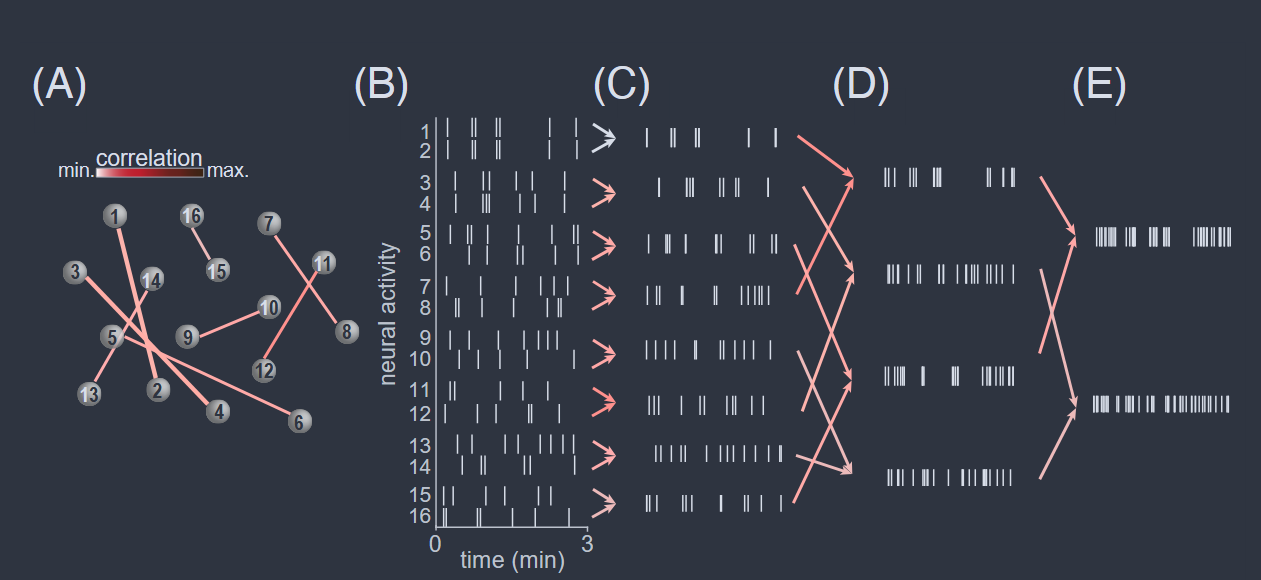
神经活动的粗粒化。 (A) 一小组神经元,链接表示最强关联的对及其关联强度。 (B) 这些细胞的动作电位示意序列。 (C) 通过对高度关联的对的活动求和进行粗粒化。 (D) 在 (C) 中找到最强相关的粗粒化变量对,并通过求和再次进行粗粒化。相关强度按 (A) 中的颜色编码。 (E) 这种 "实空间" 粗粒化的又一次迭代。
我们从变量 $\{\sigma_{i}\}$ 开始,如前所述,描述在一个小段时间窗口内所有神经元 $i = 1, 2,\cdots,N$ 的活动模式($\sigma_{i} = 1$)和静默($\sigma_{i} = 0$)。为了强调这是最微观的描述,我们将其写为 $\sigma_{i} = \sigma_{i}^{(1)}$。然后像以前一样,我们可以计算均值、协方差和关联矩阵:
$$ \begin{aligned} m_{i}^{(1)} &= \langle \sigma_{i}^{(1)}\rangle \\ C_{ij}^{(1)} &= \left\langle \left[\sigma_{i}^{(1)}-m_{i}^{(1)}\right] \left[\sigma_{j}^{(1)}-m_{j}^{(1)}\right] \right\rangle\\ c_{ij}^{(1)} &= \frac{C_{ij}^{(1)}}{\sqrt{C_{ii}^{(1)}C_{jj}^{(1)}}} \end{aligned} $$
现在我们搜索关联系数矩阵中非对角元素的最大值,然后将与该细胞对 $i, j_{*}(i)$ 相关的行和列归零,并重复。结果是一组最大相关对 $\{i, j_{*}(i)\}$,然后我们定义粗粒化变量
$$ \sigma_{i}^{(2)} = \sigma_{i}^{(1)} + \sigma_{j_{*}(i)}^{(1)} $$
现在 $i = 1, 2, \cdots , N/2$。重要的是,我们可以跨尺度迭代这个过程:我们计算变量 $\{\sigma_{i}^{(2)}\}$ 的相关矩阵并再次搜索最大相关对 $\{i, j_{*}(i)\}$,然后定义
$$ \sigma_{i}^{(3)} = \sigma_{i}^{(2)} + \sigma_{j_{*}(i)}^{(2)} $$
依此类推;在每个阶段,我们剩下 $N_{k} = \lfloor N/2^{k−1}\rfloor$ 个变量。这个粗粒化产生了 $K = 2, 4,\cdots , 2^{k−1}$ 个神经元簇,变量 $\sigma_{i}^{(k)}$ 是簇 $i$ 的总活动量。
我们强调,可以有不同的粗粒化标准和不同的变量组合方式。我们将在下面的某些点上回到这些问题(§VII.D),但现在我们探索当我们将这个最简单的方案应用于真实神经元网络时会发生什么。第一个这样的例子使用了§V中描述的 1000 多个神经元活动的实验(Meshulam 等人,2018,2019)。
我们感兴趣的是随着我们通过连续的粗粒化尺度,概率分布如何变换和流动。当然,查看联合分布 $P(\{\sigma_{i}^{(k)}\})$ 本质上是不可能的。但是,通过查看该分布的切片,甚至是单个粗粒化变量的分布,就像 Ising 模型中的磁化一样,可以学到很多东西(Binder,1981)。
由于这种粗粒化仅基于添加 "近邻" 变量,单个变量分布的一阶矩缩放必须线性:
$$ M_{1}(k) \equiv \frac{1}{N_{k}}\sum_{i=1}^{N_{k}}\langle\sigma_{i}^{(k)}\rangle = \frac{1}{N_{k}}\sum_{i=1}^{N_{k}}m_{i}^{(k)} = KM_{1}(1) $$
其中经过 $k$ 步后,我们有 $N_{k}$ 个集群,每个集群内含 $K = 2^{k−1}$ 原始变量。第一个非平凡的问题是关于二阶矩,即(结点)活动的方差,
$$ \begin{aligned} M_{2}(K) \equiv \frac{1}{N_{k}}\sum_{i=1}^{N_{k}}\left\langle \left( \sigma_{i}^{(k)} - m_{i}^{(k)} \right)^{2}\right\rangle \end{aligned} $$
请注意, 如果神经元是独立的,我们期望 $M_{2}(K)\propto K$,并且许多弱相关的群体应该在 $K$ 很大时接近这种行为。 另一方面,如果神经元是完全关联的,我们期望 $M_{2}(K)\propto K^{2}$。查看数据,在图 34A 中,我们看到对于海马体中的神经元,$M_{2}\propto K^{\widetilde{\alpha}}$,其中 $\widetilde{\alpha}= 1.4 \pm 0.06$。这种非平凡的缩放在两个数量级以上是可见的。
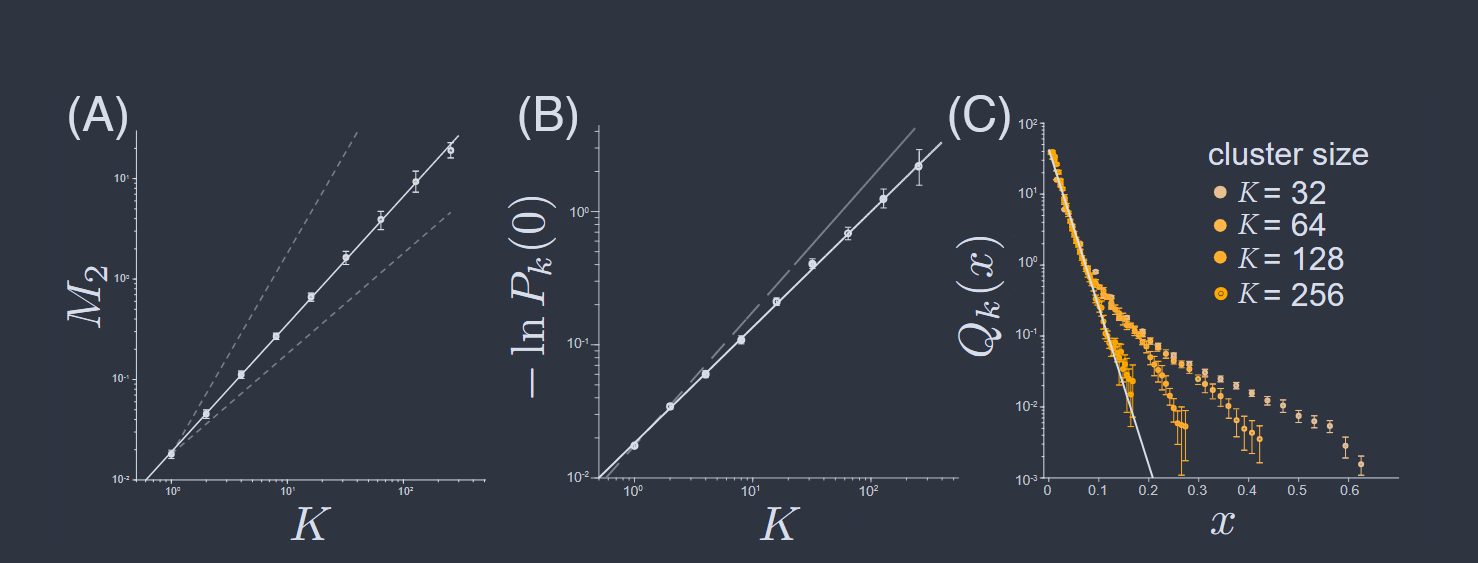
图 34 三个通过粗粒化变量分布的切片(Meshulam 等人,2018,2019)。(A) 活动方差与(实空间)粗粒化尺度的关系,来自方程(151)。实线为 $M_{2}\propto K^{\widetilde{\alpha}}$,$\widetilde{\alpha}= 1.4 \pm 0.06$;虚线为独立神经元($\widetilde{\alpha}= 1$)或完全关联神经元($\widetilde{\alpha}= 2$)的预测。(B) 静默概率与粗粒化尺度的关系。实线为方程(152),$\widetilde{\beta}= 0.88 \pm 0.01$;虚线为独立神经元的期望,$\widetilde{\beta}= 1$。(C) 归一化非零活动的分布,如方程(153)中定义。
我们可以通过询问粗粒化变量 $\sigma_{i}^{(k)} = 0$ 的概率 $P_{k}(0)$ 来获取分布的另一个切片。由于我们从变量 $\sigma_{i} = \{0, 1\}$ 开始,这与询问簇大小为 $K = 2^{k−1}$ 的所有神经元都处于静默状态的概率相同。如果神经元是独立的,我们期望一个简单的缩放 $P_{k}(0)\propto \exp{(−aK)}$,即使细胞是弱相关的,我们也期望在大 $K$ 时看到这种情况。实验上我们在图 34B 中看到
$$ P_{k}(0) = \exp{(-a K^{\widetilde{\beta}})} $$
其中指数 $\widetilde{\beta}= 0.88 \pm 0.01$。同样,缩放在两个数量级以上是精确的。
指数形式是保证能量可加($E = \sum E_{i}$), 独立分布($P = \prod P_{i}$) 的概率分布, 即 Boltzmann 概率形式 $\begin{aligned}P(\text{微观态}) = \frac{1}{Z}e^{-\beta E}\end{aligned}$. 那么群体静默是罕见事件, 概率为 $P(\text{all silent}) = q^{k} = e^{-K|\ln q|}$
自由能 $F = -k_{B}T\ln{Z}$.
如果我们想象为集群内所有神经元的联合活动建立一个显式模型,可能采用上述成对模型的形式[方程(83)],那么完全静默的概率仅依赖于配分函数,$P_{k}(0) = 1/Z$。如果我们包括更高阶项,这种情况会被推广,因此图 34B 探测了等效自由能,显然表现为 $F(K) = -aK^{\widetilde{\beta}}$。由于 $\widetilde{\beta}< 1$,自由能是亚广延的,因此在热力学极限下每个神经元的自由能将消失。这与我们在 §VI.B(图29)中看到的视网膜神经元的熵和能量相等是一致的。
更一般地,如果我们定义归一化变量 $x = \sigma^{(k)}/K$,那么
$$ P_{k}(x) = P_{k}(0)\delta_{x,0} + [1-P_{k}(0)]Q_{k}(x) $$
图 34C 显示了随着 $K$ 增加,$Q_{k}(x)$ 的演变。我们看到分布的尾部逐渐被吸收到主体中,似乎接近一个固定形式 $Q(x)\sim e^{−x/x_{0}}$。如果神经元是独立的,中心极限定理会将该分布驱动向高斯分布,但相反,我们看到了一个固定的非高斯形式的出现。
除了查看单个粗粒化变量的分布外,我们还可以查看每个大小为 $K$ 的簇内微观变量的协方差矩阵。该协方差矩阵的特征值谱取决于按 $K$ 缩放的秩,并且在很大一部分区域内,谱是一个幂 $\lambda\sim (K/\text{rank})^{\mu}$,其中 $μ = 0.71 \pm 0.06$,尽管这不如其他缩放示例那么清晰。
到目前为止,我们的讨论集中在单一时间点上变量的分布。然而,在我们理解的 RG 应用中,我们通常可以观察到动态缩放(Hohenberg 和 Halperin,1977)。直观地说,更长长度尺度上的波动需要更长时间才能弛豫,因为基础相互作用是局部的。非平凡的是,如果我们以相关时间为单位测量时间,那么对不同长度尺度粗粒化变量的相关函数会坍缩为一个通用形式,并且该相关时间本身随着长度尺度的幂变化。在完全生物学背景下,这些思想的一个优雅例子是昆虫自然群体中速度波动的动态缩放(Cavagna 等人,2017)。
对于神经元网络,我们不期望局部性是一个好的指导,但更强粗粒化的变量仍然可能具有较慢的动态,我们可以搜索动态缩放。具体来说,我们定义粗粒化尺度 $k$ 下单个变量的相关函数,
$$ \widetilde{C}_{i}^{(k)}(t) = \left\langle\left[ \sigma_{i}^{k}(t_{0})-m_{i}^{(k)} \right]\left[ \sigma_{i}^{k}(t_{0}+t)-m_{i}^{(k)} \right]\right\rangle $$
然后我们可以归一化并对簇进行平均,得到
$$ C^{(k)}(t) = \frac{1}{N_{k}}\sum_{i=1}^{N_{k}}\frac{\widetilde{C}_{i}^{(k)}(t)}{\widetilde{C}_{i}^{(k)}(0)} $$
动态缩放是假设尺度的依赖性由单一相关时间捕获,
$$ C^{(k)}(t) = C[t/\tau_{c}(k)] $$
其中 $\tau_{c}(k)\propto K^{\widetilde{z}}$。在图 35 中,我们看到对于海马体神经元群体,所有这些都有效。我们注意到,在这个实验中访问的相关时间的动态范围是有限的,在短时间内受到指示剂分子动力学的限制,在长时间内受到指数 $\widetilde{z}= 0.16 \pm 0.02$ 的小值的限制。
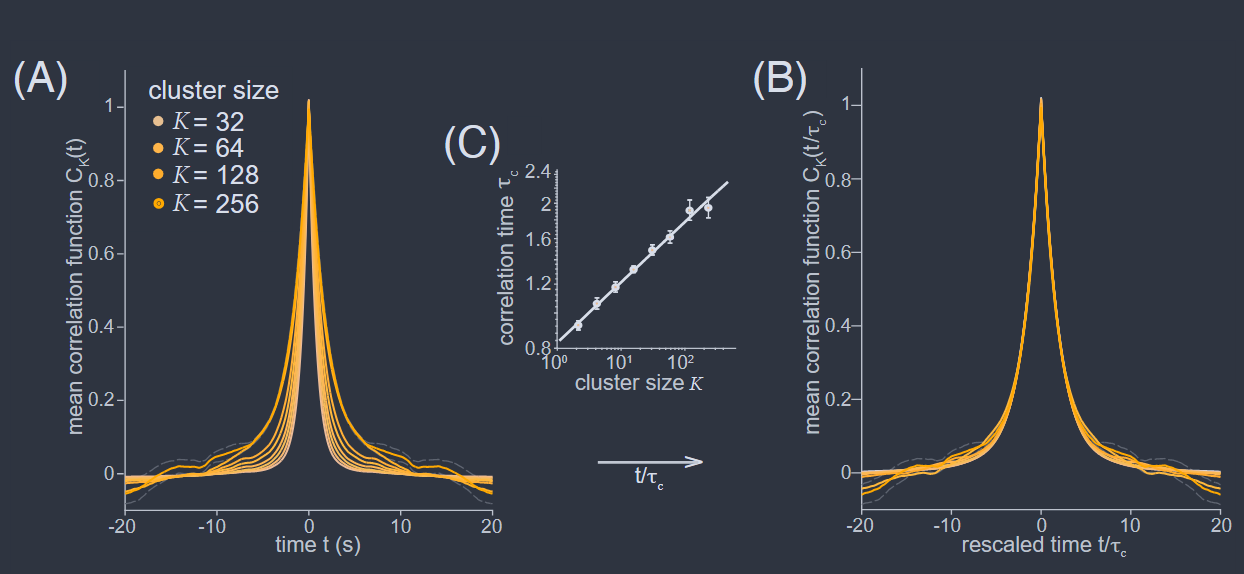
海马体中 1000 多个神经元的动态缩放(Meshulam 等人,2018)。(A) 粗粒化变量的平均相关函数,方程(155),在 $K = 2,4,\cdots, 256$ 个神经元的簇中(最浅的橙色对应于最大的簇),较大的簇表现出较慢的动态。虚线灰色表示 K = 256 神经元簇的正负一个标准差。(B) 时间轴的缩放坍缩,方程(156)。(C) 簇大小与相关时间的关系,拟合为 $\tau_{c}\propto K^{\widetilde{z}}$,其中 $\widetilde{z}= 0.16 \pm 0.02$。
重要的是,这些缩放行为并不是由我们选择用二进制变量来描述神经活动所驱动的。在这些实验中,神经活动是通过成像指示剂分子的荧光记录的,这些分子提供了一个连续的信号,如图 6 和 16 所示。我们可以对这些连续信号遵循相同的粗粒化步骤,结果是相同的(Meshulam 等人,2019)。
在 RG 的完整理论结构中,缩放指数是普适类的标志。在我们询问普适性之前,我们必须询问可重复性,尤其是在如此复杂的系统中。作为第一步,已经使用来自多只小鼠实验的数据进行了相同的分析。由于缩放在两个数量级以上是精确的,因此在单只小鼠中确定指数的误差条很小,这为可重复性设定了高标准。例如,描述自由能缩放的指数(图 34B)为 $\widetilde{\beta}= 0.87±0.014±0.015$,分别表示单次实验中的均值、均方根误差和三只小鼠实验中的标准偏差。这让人希望我们已经发现了在第二个小数位上可重复的涌现行为特征。
Morales 等人(2023)进行了更雄心勃勃的普适性搜索。他们分析了属于 Allen Institute for Brain Science 大型项目的一些实验,在这种情况下,使用多个神经像素探针(图 5)同时记录来自小鼠大脑许多不同区域的 100 多个神经元。请注意,除了探索许多不同的大脑区域外,记录活动的技术与图 34 和 35 中分析的海马体成像数据完全不同。尽管如此,所有这些大脑区域都重现了缩放的各个方面;示例包括粗粒化活动中方差的缩放(图 36A)和动态缩放(图 36B)。
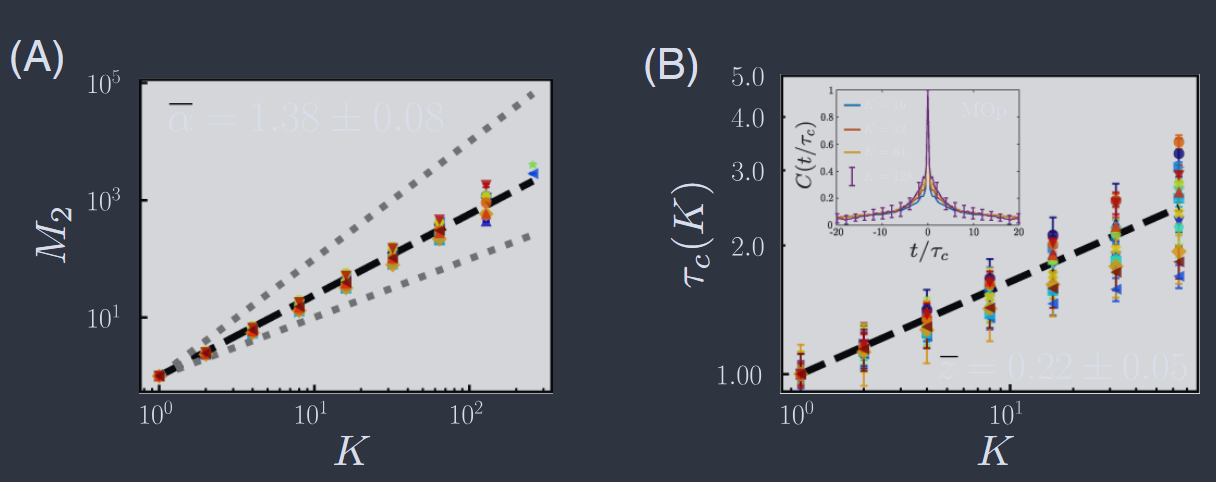
图 36 小鼠大脑多个不同区域的缩放(Moralés 等人,2023)。神经元数据经过 "实空间" (直接相关)粗粒化程序。(A) 十六个不同大脑区域中粗粒化活动的方差与簇大小的关系(以不同标记表示),可与图 34A 相对比。(B) 相同大脑区域的动态缩放。相关时间与簇大小的关系,可与图 35 相对比。插图:一个大脑区域(初级运动皮层)中神经元自相关函数的衰减,显示出一旦时间重新缩放后的坍缩。
在我们完成这篇综述时,Munn 等人(2024)报道了一个引人注目的结果。他们没有查看单个有机体中多个大脑区域的实验,而是查看了许多不同有机体的实验,从微小的线虫 C. elegans 到与我们非常相似的灵长类动物。这些实验之间存在显著的技术差异,包括钙指示蛋白(§III.C)的差异和采样率的差异;完全分辨单个神经元与 "感兴趣区域" ;以及在较小模型有机体中记录整个大脑与在较大有机体中记录单个感觉或运动区域。 这些网络的许多微观特征也非常不同,极端情况是 C. elegans 神经元产生缓慢的渐变电位,而不是离散的动作电位或尖峰。尽管存在这些警告,我们仍然可以询问这些系统中的神经活动模式如何在从两个到五个数量级的范围内通过粗粒化进行转换。图 37 显示了粗粒化活动方差 $M_{2}(k)$(来自方程(151))的结果。这些结果的明显普适性令人着迷。
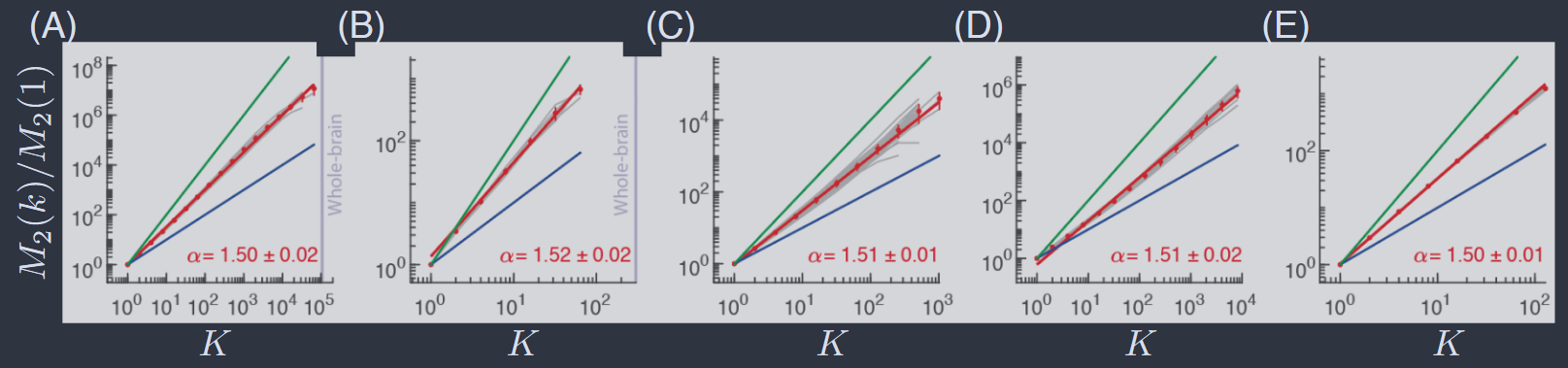
图 37 神经活动方差的缩放,方程(151),作为跨多个物种的尺度函数(Munn 等人,2024)。(A) 斑马鱼。(B) 线虫 C. elegans。(C) 果蝇 Drosophila melanogaster。(D) 小鼠初级视觉皮层。(E) 猕猴初级视觉和运动皮层。灰线是单个动物的结果,带误差的红点是物种内的均值,红线是对 $M_{2}\propto K^{\widetilde{\alpha}}$ 的拟合,指数如图所示。独立(蓝色)和完全相关(绿色)群体的期望对应于图 34A 中的虚线。
By analogy with momentum shell methods
在 "尺度" 真正是长度尺度的问题中,粗粒化是空间细节的逐渐模糊,就像我们通过显微镜观察并失焦时发生的情况一样。在这个类比中,空间模式被傅里叶变换,然后仅使用有限范围的波长进行重建。具体来说,如果我们从 $d$ 维空间中坐标为 $\vec{x}$ 的变量 $\phi(\vec{x})$ 开始,粗粒化操作变为
$$ \begin{aligned} \phi(\vec{x}) &\rightarrow \phi_{\Lambda}(\vec{x}) = z_{\Lambda}\int_{|\vec{k}|<\Lambda}\frac{\mathrm{d}^{d}k}{(2\pi)^{d}}e^{i\vec{k}\cdot\vec{x}}\widetilde{\phi}(\vec{k})\\ \widetilde{\phi}(\vec{k}) &= \int \mathrm{d}^{d}x e^{-i\vec{k}\cdot\vec{x}}\phi(\vec{x}) \end{aligned} $$
其中 $\Lambda = \pi/l$ 截断了低于长度尺度 $l$ 的贡献,$z_{\Lambda}$ 用于(重新)归一化变量;在微观类比中,这补偿了我们失焦时对比度的损失。与实空间一样,我们感兴趣的是概率分布 $P_{\lambda}[\phi_{\Lambda}]$ 如何随着截止值 $\Lambda$ 的变化而演变。由于傅里叶变量是连续的(在大系统的极限下),我们可以进行无穷小变化 $\Lambda\to\Lambda-\mathrm{d}\Lambda$。在量子力学中,波矢为 $\vec{k}$ 的波描述动量为 $\vec{p}=\hbar\vec{k}$ 的粒子,因此在范围 $\Lambda − \mathrm{d}\Lambda < |\vec{k}| < \Lambda$ 内对细节进行平均相当于在一个 "动量壳" 上积分(Wilson 和 Kogut,1974)。
在具有平移不变性的系统中,动量是守恒的。独立于这些物理原理,空间平移不变性使傅里叶变换具有特权。举例来说,如果变量 $z_{i}$ 位于点 $\vec{x}_{i}$ 的晶格上,平移不变性意味着协方差矩阵元素 $C_{ij}$ 只能依赖于位置的差异,
$$ C_{ij} = C(\vec{x}_{i} - \vec{x}_{j}) $$
该矩阵在傅里叶基中对角化,
$$ \begin{aligned} \sum_{j=1}^{N}C_{ij}u_{jr} &= \lambda_{r}u_{ir}\\ u_{jr} &\propto \exp{(i\vec{k}_{r}\cdot\vec{x}_{j})} \end{aligned} $$
我们可以根据特征值 $r$ 对模式进行排序。
在 RG 的常规应用中,大动量对应于协方差矩阵的小特征值。这表明我们可以通过滤除对应于小特征值的 "模式" 来构建粗粒化变量,而不参考空间或动量(Bradde 和 Bialek,2017)。这将粗粒化与更熟悉的数据分析技术, 主成分分析(Shlens,2014)联系起来。
具体来说,如果我们从微观变量 $\{\sigma_{i}\}$ 开始,我们可以像往常一样计算协方差矩阵
$$ C_{ij} = \langle(\sigma_{i}-\langle\sigma_{i}\rangle)(\sigma_{j}-\langle\sigma_{j}\rangle)\rangle $$
然后我们有如方程(160)所示的特征值和特征向量。让我们选择秩 $r$,使得 $\lambda_{1}\geq \lambda_{2}\cdots\lambda_{N}$。我们可以定义一个投影到对方差贡献最大的 $\hat{K}$ 个模式上,
$$ \begin{aligned} \hat{P}_{ij}(\hat{K}) &= \sum_{r=1}^{\hat{K}} u_{ir}u_{jr}\\ \phi_{\hat{K}}(i) &= z_{i}(\hat{K})\sum_{j}\hat{P}_{ij}(\hat{K})[\sigma_{i}-\langle\sigma_{i}\rangle] \end{aligned} $$
其中 $z_{i}(\hat{K})$ 为归一化(系数), 使得 $\langle[\phi_{\hat{K}}(i)]^{2}\rangle = 1$。
如前所述,我们想要跟踪单个粗粒化变量的分布,$P_{\hat{K}}(\phi_{\hat{K}})$;结果显示在图 38A 中。为了确保我们对整个矩阵 $C_{ij}$ 有控制,我们查看了通过上述实空间粗粒化识别的 $N = 128$ 个神经元的集群。然后我们可以滤除一半的模式,使得 $\hat{K} = 32$,得到的分布 $P_{\hat{K}}(\phi_{\hat{K}})$ 仍然具有一些细微结构。如果我们减少到 $\hat{K} = 32$,这些波动消失了,但分布仍然是不对称的,并且具有长尾。这种模式在我们减少到 $\hat{K} = 16$ 然后 $\hat{K} = 8$ 时继续存在,在这最后几个步骤中,分布几乎没有变化。这表明随着我们进行粗粒化,分布趋向于一个固定形式。重要的是,这种形式与如果相关性较弱,中心极限定理所保证的高斯形式非常不同。
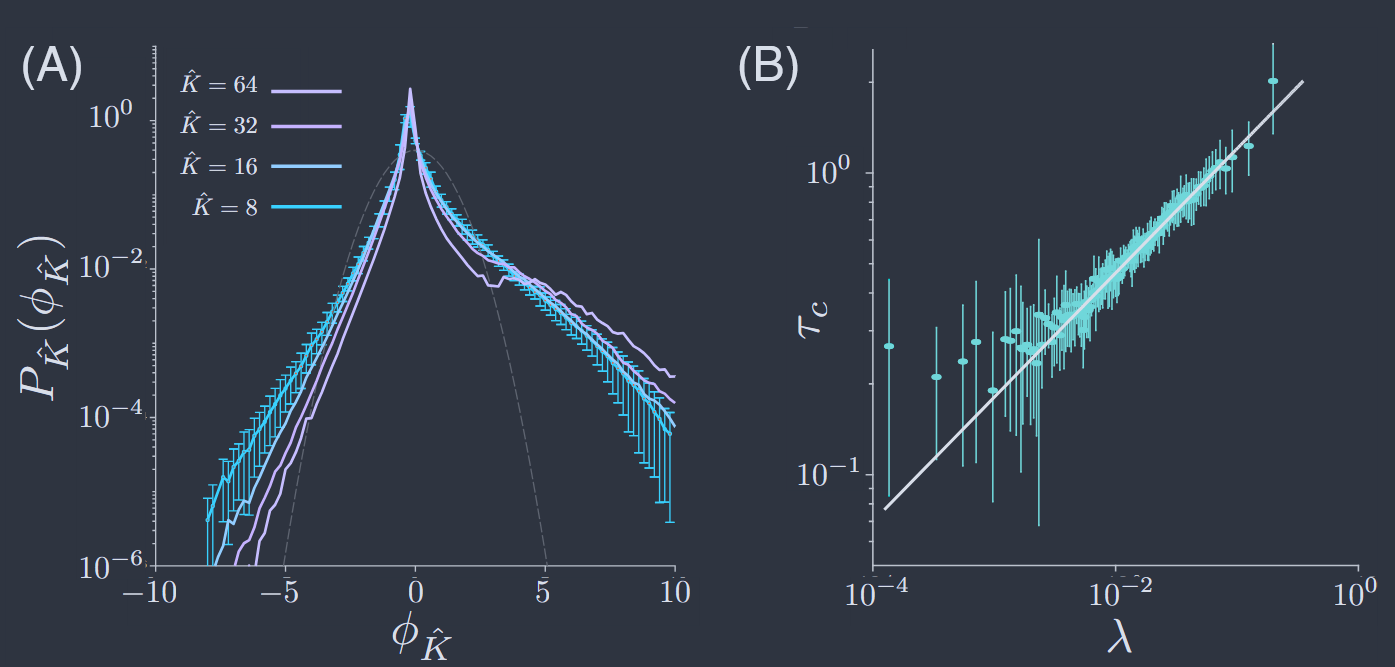
图 38 通过 "动量壳" 对 $N = 128$ 个神经元进行粗粒化(Meshulam 等人,2018)。(A) 跟踪来自方程(164)的单个粗粒化变量的分布。不同颜色对应于保留不同数量的模式 $\hat{K}$,如插图所示;虚线为高斯分布以供比较。(B) 模式 $r$ 中波动的相关时间的动态缩放,方程(166),与协方差矩阵的相关特征值 $\tau_{c}(r)\propto \lambda_{r}^{\widetilde{z}^{\prime}}$,其中 $\widetilde{z}^{\prime} = 0.37 \pm 0.04$。
动态缩放的直觉是,更大长度尺度上的波动弛豫得更慢,尽管 "尺度" 的含义现在更抽象(图 35),但我们已经看到这可以推广到神经元网络。通过转换到对协方差矩阵进行对角化的基,我们已经隔离了在二阶上独立的波动模式,自然会问这些模式上的波动是如何弛豫的。沿模式 $r$ 的变化定义为
$$ \widetilde{\phi}_{r} = \sum_{i=1}^{N}[\sigma_{i}-\langle\sigma_{i}\rangle]u_{ir} $$
相关函数为
$$ C_{r}(t) = \langle\widetilde{\phi}_{r}(t_{0})\widetilde{\phi}_{r}(t_{0}+t)\rangle $$
动态缩放是这样一种说法:当时间按单一相关时间进行缩放时,所有这些相关性都会坍缩,并且该相关时间本身具有尺度的幂律依赖。在通常的例子中,这意味着 $\tau_{c}\propto |\vec{k}|^{z}$(Hohenberg 和 Halperin,1977),但在临界点附近,协方差矩阵的特征值也对 $|\vec{k}|$ 具有幂律依赖,因此我们可以直接测试 $\tau_{c}\propto \lambda^{\widetilde{z}^{\prime}}$,如图 38B 所示。如前所述,最短的相关时间受到报告电活动的荧光蛋白响应时间的限制,最长的时间受到动态缩放指数大小的限制;尽管如此,我们仍然可以观察到 $\lambda$ 上两个数量级的相当精确的缩放。
通过查看模式的相关时间找到的动态指数 $\widetilde{z}^{\prime}$ 应该与我们通过实空间粗粒化看到的指数 $\widetilde{z}$(图 35C) 相关,通过描述协方差矩阵特征值衰减的指数 $\mu$,$\widetilde{z} = \mu\widetilde{z}^{\prime}$。这确实有效,尽管误差条很大(Meshulam 等人,2018)。更重要的是,这些结果表明网络没有单一的特征时间尺度,而是一个连续的时间尺度,可以通过在不同尺度上探测来访问。
RG as a path to understanding
如果我们相信在神经网络功能和活动的复杂性中可以找到潜在的简单性,我们可能想暂停片刻来说服自己,遵循 RG 简化实际上可以引导我们到达那里。鉴于在获得越来越多神经元数据集方面的爆炸性实验进展,如上面的例子所示,这一追求现在感觉是可以实现的。虽然我们可能不知道如何操纵大脑中的 "温度" 或 "磁化强度" ,但我们正在通过监测的神经元数量获得数十年的进步。
重整化群是一个强大的理论结构。由于我们没有神经动力学的微观模型,我们还无法利用这个结构。相反,我们采用了一种受 RG 启发的数据分析方法,这被描述为 "现象学重整化群" (Nicoletti 等人,2020)或 "迭代粗粒化" (Munn 等人,2024)。如果我们将这些方法应用于理解良好的平衡统计力学问题,最有趣的结果将是概率分布朝着某种固定的非高斯形式流动,以及沿着这条轨迹出现幂律缩放,就像在临界点发生的那样。值得注意的是,这正是所发现的,无论是在对海马体的初始应用中,还是现在在许多其他系统中;缩放指数是可重复的,甚至可能是普适的。很容易得出结论,基础网络动力学必须由重整化群的非平凡不动点描述的理论来描述。
我们应该保持谨慎。是否有可能我们与 RG 不动点相关联的一些粗粒化行为可以更普遍地出现在非平衡系统中?Nicoletti 等人(2020)通过分析接触过程的模拟来解决这个问题,在该过程中,二进制变量以与邻近位置活跃变量密度成正比的单位时间概率被激活,然后以固定的单位时间概率被停用。该模型有一个参数,即激活率中的比例常数,并且存在一个取决于网络几何形状的临界值(Marro 和 Dickman,1999)。在临界点以下,完全不活跃状态是吸收态,因此问题是现象学 RG 是否可以区分临界点与超临界行为。
也许令人惊讶的是,即使远离临界点,我们也可以在某些量中看到(弱)非平凡的缩放行为,如图 39A 所示的活动方差。但其他量即使非常接近临界性也显示出明显的偏离缩放行为,如图 39B 所示的相关时间。明确无误的是,在临界点处,粗粒化变量的概率分布朝着非平凡的固定形式流动,而在其他情况下则朝着高斯形式流动。我们可以通过实空间粗粒化(图 39C)或通过动量壳(图 39D)来看到这一点。Nicoletti 等人(2020)强调,现象学 RG 可以明确地识别临界点,但前提是我们检查了全范围的行为。
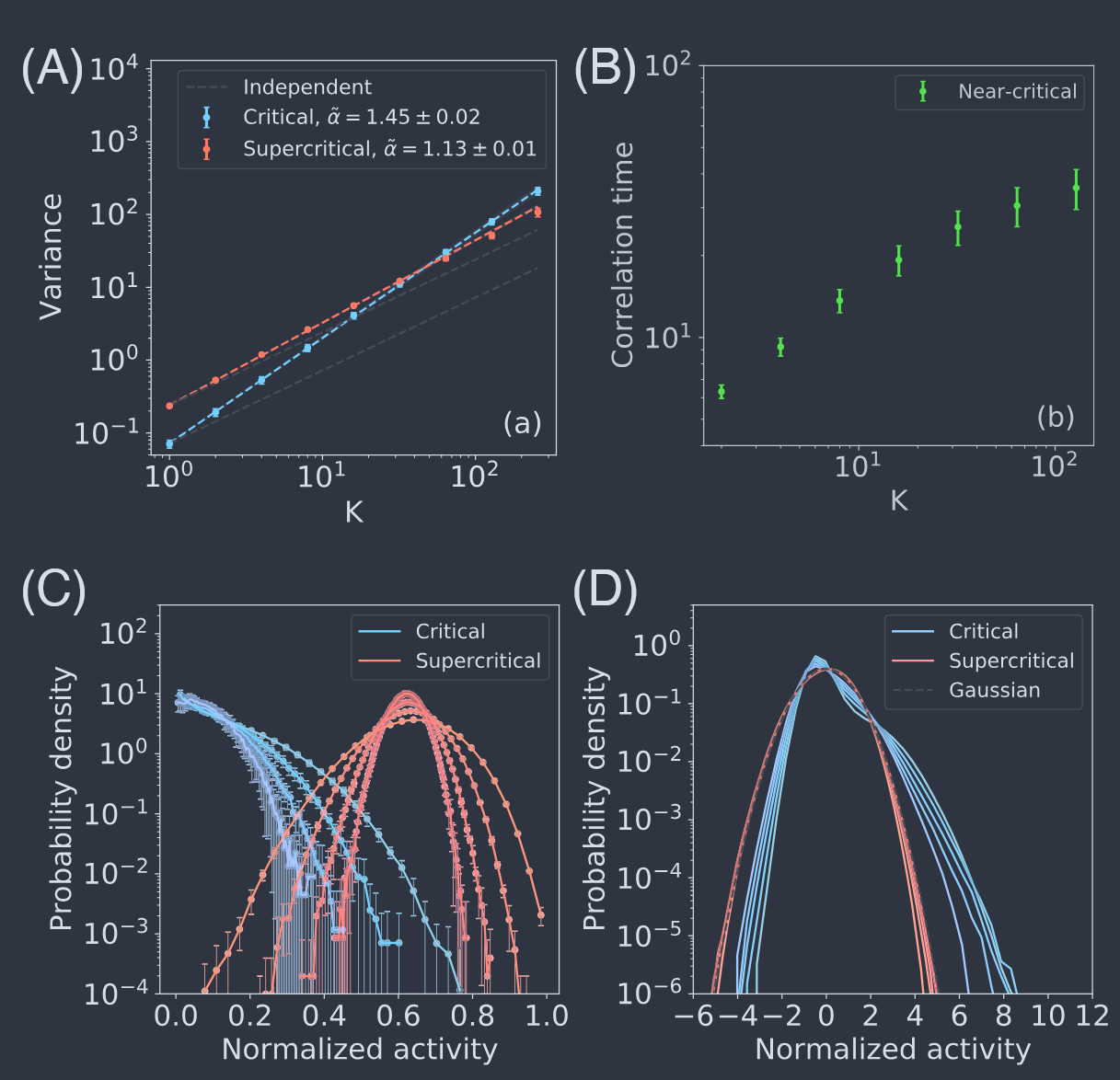
图 39 接触过程的粗粒化(Nicoletti 等人,2020)。(A) 实空间中粗粒化尺度与活动方差的关系,如图 34A 和 37 所示。临界性下的行为(蓝色)明显不同于超临界情况(红色),后者系统地但弱地偏离了独立变量的预期(虚线)。(B) 实空间中粗粒化尺度与相关时间的关系,如图 35 所示。控制参数设置接近其临界值,我们在小 $K$ 处看到缩放的迹象,但在大 $K$ 处明显偏离。(C) 临界性下(蓝色)和远离临界性(红色)时,$K = 32,64, 128, 256$ 的单个粗粒化变量的分布。在这两种情况下,我们都看到了朝着固定分布的流动,但远离临界性时,这符合中心极限定理所预期的高斯分布。(D) 与 (C) 类似,但通过动量壳进行粗粒化,保留 $N/8, N/16, N/32, N/64, N/128$ 个模式。
正如在 VI.D 中(相关)关于临界性的讨论中所提到的那样,有人建议通过迭代粗粒化发现的一些现象可以在神经元独立响应潜在场的模型中再现(Morrell 等人,2021)。在这种观点中,缩放和朝向固定分布的流动是近似的,并且不清楚为什么缩放指数应该在动物之间是可重复的;如图 37 所示,更广泛的普适性概念将更难理解。
毫无疑问,缩放行为从潜在变量模型中普遍出现的建议是错误的。考虑这样一种模型,其中作用在每个神经元 $i$ 上的有效场是从高斯分布中抽取的 $K$ 个潜在变量的线性组合。如果场是弱的,那么神经活动的协方差矩阵与场的协方差矩阵具有相同的秩。这个简单的结果在更强的场下失效,但即使在无限强场的极限下,协方差矩阵的特征值谱中仍然存在一个间隙,至少对于典型参数选择来说是这样,因此不可能恢复精确的缩放行为。
我们注意到,具体的、生物学动机的潜在场模型——§VI.D 中讨论的独立位置细胞模型——未能表现出缩放行为(Meshulam 等人,2018)。这个结果或许并不令人惊讶。在位置细胞群体中,有两个长度尺度,即位置场的近似宽度和位置场中心之间的平均距离。在为此处分析的海马体实验提供背景的一维(虚拟)环境中,这些长度的比率给了我们一个特征神经元数,$K_{c}\sim 18$。实际上,对应于图 34A、B 的独立位置细胞模型的分析显示在 $K \sim K_{c}$ 处有 "断点" 。虽然这些都是近似陈述,但它们突显了这样一个事实:在存在如此明显尺度的情况下,在静态和动态量中观察到相当精确的幂律缩放确实令人惊讶。
面对高维观察,一个自然的反应是寻找一个低维描述。在某种意义上,重整化群是相反的方法(Bradde 和 Bialek,2017)。与寻找正确的维数以投影数据不同,RG 邀请我们检查当我们移动忽略的细节和保留的特征之间的边界时,我们的描述如何变化。事情简化了,不是因为我们有更少的自由度,而是因为描述这些自由度的模型朝着更简单、更普遍的东西流动。到目前为止的证据指向这样一种简化描述的存在。从理论方面来看,对更现实神经元网络模型进行 RG 分析的初步努力表明,这些模型由新的普适类描述(Brinkman,2023)。
我们在这里没有强调的是粗粒化与更功能性行为的联系。在海马体中,位置如何在粗粒化变量中表示?更一般地说,细粒化和粗粒化变量是否实现了编码感官世界的不同原则(Munn 等人,2024)?当大脑在不同的全局状态之间切换时,神经元的局部网络能否访问不同的缩放轨迹(Castro 等人,2024)?随着粗粒化成为分析大规模神经记录中更常用的工具,我们预计在未来几年内在这些问题上会取得进展。
在平衡临界现象中,对缩放的最详细测试跨越了六个数量级,精度优于百分之一(Lipa 等人,1996)。如 §§III.B 和 III.C 所述,实验前沿正朝着同时记录 $\sim 10^{6}$ 个神经元的方向发展。这为我们打开了一个可能性,可以在单细胞分辨率下跨越五个数量级跟踪粗粒化轨迹,并将误差条降低到更有限范围内的百分之一水平。将现有工具扩展到具有更大脑容量的生物体也意味着我们将在单个大脑区域中看到更多神经元的同时记录,在这些区域中缩放似乎更有可能。我们已经看到这些分析中出现的量可以在小数点后第二位上重复的迹象。一种可能性是,新的、更大的实验将揭示不同尺度上不同机制之间的交叉。或者,到目前为止看到的缩放行为可能被证明是基本上是精确的。无论结果如何,想到对真实、功能性大脑的实验很快就能达到与平衡临界现象相当的精度,这都是非凡的。对理论的相应挑战应该是明确的。