
Abstract
Real-time decoding of neural activity is central to neuroscience and neurotechnology applications, from closed-loop experiments to brain-computer interfaces, where models are subject to strict latency constraints.
Traditional methods, including simple recurrent neural networks, are fast and lightweight but often struggle to generalize to unseen data. In contrast, recent Transformer-based approaches leverage large-scale pretraining for strong generalization performance, but typically have much larger computational requirements and are not always suitable for lowresource or real-time settings.
实时解码神经活动 是神经科学和神经技术应用的核心,从闭环实验到脑机接口,模型都受到严格的延迟限制。
传统方法,包括简单的循环神经网络,速度快且轻量,但通常难以推广到未见过的数据。相比之下,最近基于 Transformer 的方法利用大规模预训练实现了强大的泛化性能,但通常具有更大的计算需求,并不总是适合低资源或实时设置。
To address these shortcomings, we present POSSM, a novel hybrid architecture that combines individual spike tokenization via a cross-attention module with a recurrent state-space model (SSM) backbone to enable
- fast and causal online prediction on neural activity and
- efficient generalization to new sessions, individuals, and tasks through multi-dataset pretraining.
为了解决这些缺点,我们提出了 POSSM,这是一种新颖的混合架构,结合了通过 交叉注意力模块 进行的单个脉冲标记化与循环状态空间模型(SSM)骨干,以实现
- 对神经活动的快速和因果在线预测,以及
- 通过多数据集预训练实现对新会话、个体和任务的高效泛化。
We evaluate POSSM’s decoding performance and inference speed on intracortical decoding of monkey motor tasks, and show that it extends to clinical applications, namely handwriting and speech decoding in human subjects.
Notably, we demonstrate that pretraining on monkey motor-cortical recordings improves decoding performance on the human handwriting task, highlighting the exciting potential for cross-species transfer. In all of these tasks, we find that POSSM achieves decoding accuracy comparable to state-of-the-art Transformers, at a fraction of the inference cost (up to 9× faster on GPU). These results suggest that hybrid SSMs are a promising approach to bridging the gap between accuracy, inference speed, and generalization when training neural decoders for real-time, closed-loop applications.
我们评估了 POSSM 在猴子运动任务的皮层内解码中的解码性能和推理速度,并展示了它在临床应用中的扩展,即人类受试者的手写和语音解码。
值得注意的是,我们证明了在猴子运动皮层记录上的预训练提高了人类手写任务的解码性能,突显了跨物种转移的令人兴奋的潜力。在所有这些任务中,我们发现 POSSM 以 GPU 上高达 9 倍的速度实现了与最先进 Transformer 相当的解码精度。这些结果表明,混合 SSM 是一种有前途的方法,可以弥合实时闭环应用中训练神经解码器时准确性、推理速度和泛化之间的差距。
Introduction
Neural decoding – the process of mapping neural activity to behavioural or cognitive variables – is a core component of modern neuroscience and neurotechnology.
As neural recording techniques evolve and datasets grow in size, there is increasing interest in building generalist decoders that scale and flexibly adapt across subjects and experiments.
Several important downstream applications including closed-loop neuroscience experiments and brain-computer interfaces (BCIs) – require fine-grained, low-latency decoding for real-time control. Advances in these technologies would enable next-generation clinical interventions in motor decoding, speech prostheses, and closed-loop neuromodulation.
神经解码——将神经活动映射到行为或认知变量的过程——是现代神经科学和神经技术的核心组成部分。
随着神经记录技术的发展和数据集规模的增长,越来越多的人对构建通用解码器感兴趣,这些解码器可以跨受试者和实验进行扩展和灵活适应。
一些重要的下游应用,包括闭环神经科学实验和 脑机接口(BCI)——需要高精细度、低延迟的解码以实时控制。这些技术的进步, 将使下一代临床干预措施(运动解码、语音假体和闭环神经调节)成为可能。
Building towards these applications will require neural decoders that meet three requirements:
- robust and accurate predictions,
- causal, low-latency inference that is viable in an online setting, and
- flexible generalization to new subjects, tasks, and experimental settings.
Although recent developments in machine learning (ML) have enabled significant strides in each of these axes, building a neural decoder that achieves all three remains an open challenge.
实现这些应用需要满足三个要求的神经解码器:
- 稳健且准确的预测,
- 因果、低延迟的推理,在在线环境中可行,以及
- 对新受试者、任务和实验设置的灵活泛化。
尽管 机器学习(ML) 的最新发展在这些方面取得了重大进展,但构建一个同时实现这三点的神经解码器仍然是一个未解决的挑战。
Recurrent neural networks (RNNs) and attention-based models such as Transformers have shown significant promise for neural decoding tasks.
RNNs (Figure 1a) offer fast, low-latency inference on sequential data and strong performance when trained on specific tasks.
However, their ability to generalize to new subjects is limited due to their rigid input format. Specifically, their reliance on fixed-size, time-binned inputs means that they typically cannot learn from new sessions with different neuron identities or sampling rates without full re-training and/or modifying the architecture.
循环神经网络(RNN) 和 基于注意力的模型(如 Transformer)在神经解码任务中显示出显著的前景。
RNN(图 1a)在序列数据上提供快速、低延迟的推理,并在特定任务上训练时表现出色。
然而,由于其硬性的输入格式,它们对新受试者的泛化能力有限。具体来说,它们依赖于固定大小的时间分箱输入,这意味着如果不完全重新训练和/或修改架构, 它们通常无法从具有不同神经元身份或采样率的新情景中学习。
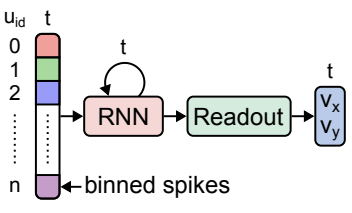
In contrast, Transformerbased architectures (Figure 1b) offer greater flexibility thanks to more adaptable neural tokenization approaches.
Nonetheless, they struggle with applications involving real-time processing due to their quadratic computational complexity, in addition to the overall computational load of the attention mechanism.
Recent efforts in sequence modelling with large language models have explored hybrid architectures that combine recurrent layers, such as gated recurrent units (GRUs) or state-space models (SSMs), with attention layers.
These models show encouraging gains in long-context understanding and computational efficiency. While hybrid attention-SSM approaches offer a promising solution for real-time neural decoding, to the best of our knowledge, they remain unexplored in this area.
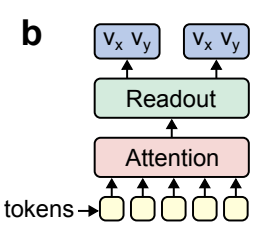
相比之下,基于 Transformer 的架构(图 1b)由于更灵活的神经标记化方法而提供了更大的灵活性。
尽管如此,由于其二次计算复杂性以及注意力机制的整体计算负载,它们在涉及实时处理的应用中仍然存在困难。
最近在 大语言模型 的序列建模方面的努力探索了将 门控循环单元(GRU) 或 状态空间模型(SSM) 等循环层与注意力层相结合的混合架构。
这些模型在长上下文理解和计算效率方面显示出令人鼓舞的提升。虽然混合注意力-SSM 方法为实时神经解码提供了有前途的解决方案,但据我们所知,它们在该领域仍未被探索。
We address this gap with POSSM, a hybrid model that combines the flexible input-processing of Transformers with the efficient, online inference capabilities of a recurrent SSM backbone.
Unlike traditional methods that rely on rigid time-binning, POSSM operates at a millisecond-level resolution by tokenizing individual spikes. In essence, POSSM builds on a POYO-style cross-attention encoder that projects a variable number of spike tokens to a fixed-size latent space. The resulting output is then fed to an SSM that updates its hidden state across consecutive chunks in time.
我们通过 POSSM 填补了这一空白,这是一种混合模型,结合了 Transformer 的灵活输入处理和递归 SSM 骨干的高效在线推理能力。
与依赖 刚性时间分箱 的传统方法不同,POSSM 通过对单个脉冲进行标记化,在毫秒级分辨率下运行。本质上,POSSM 建立在 POYO 风格的交叉注意力编码器之上,该编码器将可变数量的脉冲标记投影到固定大小的潜在空间。然后将生成的输出馈送到 SSM,该 SSM 在连续时间块中更新其隐藏状态。
This architecture, as illustrated in Figure 2, offers two key benefits:
- the recurrent backbone allows for lightweight, constant-time predictions over consecutive chunks of time and
- by adopting POYO’s spike tokenization, encoding, and decoding schemes, POSSM can effectively generalize to different sessions, tasks, and subjects.
如图 2 所示,这种架构提供了两个关键优势:
- 循环骨干允许对连续时间块进行轻量级、恒定时间的预测;
- 通过采用 POYO 的脉冲标记化、编码和解码方案,POSSM 可以有效地泛化到不同的会话、任务和受试者。
Figure 2: An architecture for generalizable, real-time neural decoding. POSSM combines individual spike tokenization and input-output cross-attention with a recurrent SSM backbone. In this paper, we typically consider $k = 3$ and $T_{c} = 50\text{ ms}$.
图 2:一种通用的实时神经解码架构。POSSM 结合了单个脉冲标记化和输入输出交叉注意力与循环 SSM 骨干。在本文中,我们通常考虑 $k = 3$ 和 $T_{c} = 50\text{ ms}$。
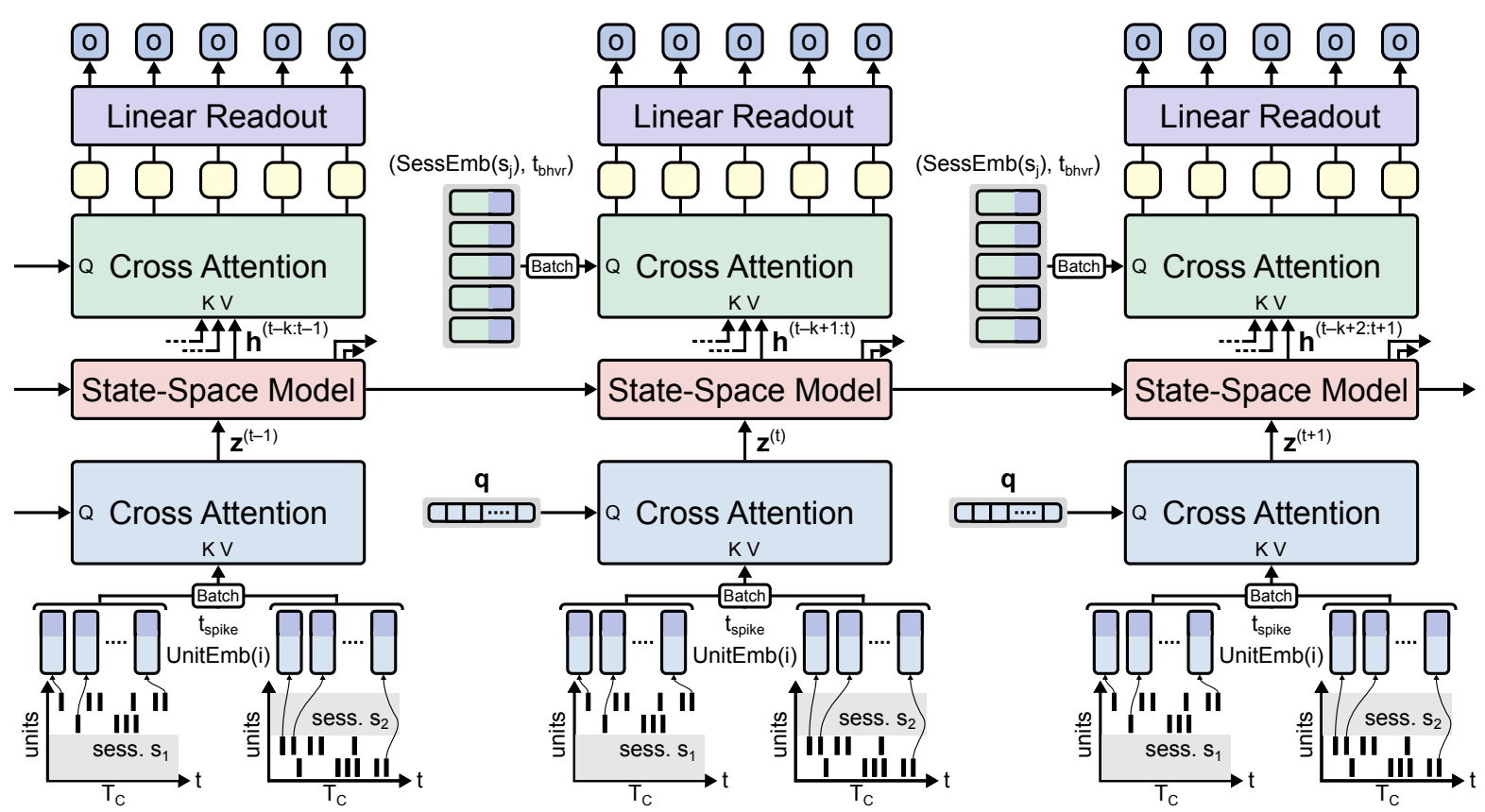
In this paper, we introduce the POSSM architecture and evaluate its performance on intracortical recordings of spiking activity from experiments in both non-human primates (NHPs) and humans.
Although our current evaluations are conducted offline, POSSM is designed for real-time inference and can be readily implemented for online experiments.
Finally, while this paper is concerned with invasive electrophysiology recordings, this method could be extended further to other modalities using POYO-style tokenization (see Section 5 for a discussion). Our contributions are summarized as follows:
在本文中,我们介绍了 POSSM 架构,并评估了其在 非人类灵长类动物(NHP) 和人类实验中脉冲活动皮层内记录的性能。
尽管我们当前的评估是在离线进行的,但 POSSM 旨在实现 实时推理,并且可以很容易地实现在线实验。
最后,虽然本文关注的是侵入性电生理记录,但该方法可以进一步扩展到使用 POYO 风格标记化的其他模态(有关讨论,请参见第 5 节)。我们的贡献总结如下:
- Performance and efficiency: We evaluate POSSM against other popular models using NHP datasets that contain multiple sessions, subjects, and different reaching tasks (centre-out, random target, maze, etc.). We find that POSSM matches or outperforms other models on all these tests, doing so with greater speed and significantly reduced computational cost.
- 表征和效率:我们使用包含多个会话、受试者和不同到达任务(中心外、随机目标、迷宫等)的 NHP 数据集评估 POSSM 与其他流行模型的性能。我们发现 POSSM 在所有这些测试中都能匹配或优于其他模型,并且速度更快,计算成本显著降低。
- Multi-dataset pretraining improves performance: Through large-scale pretraining, we find that POSSM delivers improved performance on NHP datasets across sessions, subjects, and even tasks.
- 多数据集预训练提高了性能:通过大规模预训练,我们发现 POSSM 在 NHP 数据集的各个会话、受试者甚至任务上都提供了改进的性能。
- Cross-species transfer learning: Pretraining on diverse NHP datasets and then finetuning POSSM leads to state-of-the-art performance when decoding imagined handwritten letters from human cortical activity. This cross-species transfer not only outlines the remarkable transferability of neural dynamics across different primates, but also shows the potential for leveraging abundant non-human data to augment limited human datasets for improved decoding performance.
- 跨物种迁移学习:在多样化的 NHP 数据集上进行预训练,然后微调 POSSM,在解码人类皮层活动中想象的手写字母时实现了最先进的性能。这种跨物种转移不仅概述了不同灵长类动物之间神经动力学的显著可转移性,还展示了利用丰富的非人类数据来增强有限的人类数据集以提高解码性能的潜力。
- Long sequence complex decoding: When trained on human motor-cortical data during attempted speech, POSSM achieves strong decoding performance. In contrast, attentionbased models struggle with the task’s long-context demands, making them computationally prohibitive.
- 长序列复杂解码:在尝试语音时对人类运动皮层数据进行训练时,POSSM 实现了强大的解码性能。相比之下,基于注意力的模型在任务的长上下文需求方面存在困难,使得它们在计算上变得不可行。
Methods
We focus on decoding neuronal spiking activity, which consists of discrete events triggered when excitatory input to a neuron exceeds a certain threshold.
The timing and frequency of spikes encode information conveyed to other neurons throughout the brain, underlying a communication system that is central to all neural function.
我们专注于解码神经元脉冲活动,这些活动由当神经元的兴奋性输入超过某个阈值时触发的离散事件组成。
脉冲的时机和频率编码传递给大脑其他神经元的信息,构成了神经功能的核心通信系统。
However, their sparse nature requires an effective input representation that can handle their temporal irregularity.
Furthermore, there exists no direct mapping between the neurons of one living organism to another, highlighting the non-triviality of the alignment problem when training across multiple individuals.
In this section, we describe how POSSM is designed to sequentially process sub-second windows of these spikes for the online prediction of behaviour, while maintaining a flexible input framework that allows it to efficiently generalize to an entirely new set of neurons during finetuning.
然而,它们的 稀疏性质 需要一种有效的输入表示来处理它们的时间不规则性。
此外,不同生物体的神经元之间不存在直接映射,这突显了在多个个体之间训练时 对齐问题 的非平凡性。
在本节中,我们描述了 POSSM 如何设计用于序列处理这些脉冲的亚秒窗口,以实现行为的在线预测,同时保持灵活的输入框架,使其能够在微调期间有效地推广到一组全新的神经元。
Input processing
Streaming neural activity as input
Our focus is on real-time performance, which requires minimal latency between the moment that neural activity is observed and when a corresponding prediction is generated. This constraint significantly limits the time duration, and consequently the amount of data, that a model can use for each new prediction.
我们专注于实时性能,这需要在观察到神经活动的时刻和生成相应预测之间的延迟最小化。这个限制显著限制了模型可以用于每个新预测的时间持续时间,因此也限制了数据量。
To this end, POSSM maintains a hidden state as data is streamed in, allowing it to incorporate past information without reprocessing previous inputs. In each chunk, the number of spikes varies, meaning each input is represented as a variable-length sequence of spikes.
While POSSM generally uses contiguous 50 ms time chunks here, we also demonstrate strong performance with 20 ms chunks (see Section D.1). In theory, these windows could even be shorter or longer (and even overlapping) depending on the task, with the understanding that there would be some trade-off between temporal resolution and computational complexity.
为此,POSSM 在数据流入时保持隐藏状态,使其能够结合过去的信息而无需重新处理先前的输入。在每个块中,脉冲数量各不相同,这意味着每个输入表示为可变长度的脉冲序列。
虽然 POSSM 通常在这里使用连续的 50 毫秒时间块,但我们还展示了使用 20 毫秒块时的强大性能(见第 D.1 节)。理论上,这些窗口甚至可以更短或更长(甚至重叠),具体取决于任务,同时理解在时间分辨率和计算复杂性之间会有一些权衡。
Spike tokenization.
We adopt the tokenization scheme from the original POYO model, where each neuronal spike is represented using two pieces of information:
- the identity of the neural unit which it came from and
- the timestamp at which it occurred (see Figure 2).
The former corresponds to a unique learnable unit embedding for each neuron, while the latter is encoded with a rotary position embedding (RoPE) that allows the tokens to be processed based on their relative timing rather than their absolute timestamps.
我们采用了原始 POYO 模型的标记化方案,其中每个神经元脉冲使用两条信息表示:
- 它来自的神经单元的身份
- 它发生的时间戳(见图 2)。
前者对应于每个神经元的唯一可学习单元嵌入,而后者则使用 旋转位置嵌入(RoPE) 进行编码,允许基于相对时间而非绝对时间戳处理标记。
For example, a spike from some neuron with integer ID $i$ that occurs at time $t_{\text{spike}}$ would be represented as a $D$-dimensional token $x$, given by:
$$ x = (\text{UnitEmb}(i), t_{\text{spike}}), $$
where $\text{UnitEmb}$ : $\mathbb{Z}\to \mathbb{R}^D$ is the unit embedding map and $D$ is a hyperparameter. As tokenization is an element-wise operation, a time chunk with $N$ spikes will yield $N$ spike tokens.
例如,某个神经元的脉冲,其整数 ID 为 $i$,发生在时间 $t_{\text{spike}}$,将表示为一个 $D$ 维标记 $x$,表示为:
$$ x = (\text{UnitEmb}(i), t_{\text{spike}}), $$
其中 $\text{UnitEmb}$ : $\mathbb{Z}\to \mathbb{R}^D$ 是单元嵌入映射,$D$ 是一个超参数。由于标记化是一个逐元素操作,具有 $N$ 个脉冲的时间块将产生 $N$ 个脉冲标记。
We opt to use the general term “neural unit”, as spikes could be assigned at a coarser specificity than an individual neuron (e.g., multi-unit activity on a single electrode channel) depending on the dataset and task at hand.
This flexibility, coupled with the model’s ability to handle a variable number of units, facilitates both training and efficient finetuning (see Section 2.3) on multiple sessions and even across datasets.
我们选择使用通用术语“神经单元”,因为根据手头的数据集和任务,脉冲可以分配得比单个神经元更粗糙(例如,单个电极通道上的多单元活动)。
这种灵活性,加上模型处理可变数量单元的能力,有助于在多个会话甚至跨数据集进行训练和高效微调(见第 2.3 节)。
Architecture
Input cross-attention
We employ the original POYO encoder, where a cross-attention module inspired by the PerceiverIO architecture compresses a variable-length sequence of input spike tokens into a fixed-size latent representation. Unlike POYO, however, the encoder is applied on short 50 ms time chunks, each of which is mapped to a single latent vector.
我们采用了原始 POYO 编码器,其中受 PerceiverIO 架构 启发的交叉注意力模块将可变长度的输入脉冲标记序列压缩为固定大小的潜在表示。然而,与 POYO 不同,编码器应用于短的 50 毫秒时间块,每个时间块映射到单个 潜在向量。
This is achieved by setting the spike tokens as the attention keys and values, and using a learnable query vector $q\in \mathbb{R}^{1\times M}$ , where $M$ is a hyperparameter. Given a sequence $X_{t} = [x_{0}, x_{1}, \dots, x_{N}]^{\top}\in \mathbb{R}^{N\times D}$ of $N$ spike tokens from some chunk of time indexed by $t$, the latent output of the cross-attention module is computed as such:
$$ z^{(t)} = \text{softmax}\left(\frac{qK_{t}^{\top}}{\sqrt{D}}\right)V_{t} $$
where $K_{t} = X_{t}W_{k}$ and $V_{t} = X_{t}W_{v}$, with $W_{k}, W_{v}\in \mathbb{R}^{D\times M}$ , are the projections of the input token sequence, following standard Transformer notation. Following POYO, our implementation also uses the standard Transformer block with pre-normalization layers and feed-forward networks.
通过将脉冲标记设置为注意力键和值,并使用可学习的查询向量 $q\in \mathbb{R}^{1\times M}$ 实现这一点,其中 $M$ 是一个超参数。给定某个时间块索引为 $t$ 的 $N$ 个脉冲标记序列 $X_{t} = [x_{0}, x_{1}, \dots, x_{N}]^{\top}\in \mathbb{R}^{N\times D}$,交叉注意力模块的潜在输出计算如下:
$$ z^{(t)} = \text{softmax}\left(\frac{qK_{t}^{\top}}{\sqrt{D}}\right)V_{t} $$
其中 $K_{t} = X_{t}W_{k}$ 和 $V_{t} = X_{t}W_{v}$,$W_{k}, W_{v}\in \mathbb{R}^{D\times M}$ 是输入标记序列的投影,遵循标准 Transformer 符号。按照 POYO 的做法,我们的实现还使用了带有预归一化层和前馈网络的标准 Transformer 块。
Recurrent backbone
The output of the cross-attention $z^{(t)}$ is then fed to an SSM (or another variety of RNN), which we refer to as the recurrent backbone. The hidden state of the recurrent backbone is updated as follows:
$$ h^{(t)} = f_{\text{SSM}}(z^{(t)}, h^{(t−1)}). $$
While the input cross-attention captures local temporal structure (i.e., within the 50 ms chunk), the SSM integrates this information with historical context through its hidden state, allowing POSSM to process information at both local and global timescales. We run experiments with three different backbone architectures: diagonal structured state-space models (S4D), GRU, and Mamba. However, we wish to note that this method is compatible with any other type of recurrent model. Specifics regarding each of these backbone architectures can be found in Section B.2.
交叉注意力的输出 $z^{(t)}$ 然后被馈送到 SSM(或其他类型的 RNN),我们称之为循环骨干。循环骨干的隐藏状态更新如下:
$$ h^{(t)} = f_{\text{SSM}}(z^{(t)}, h^{(t−1)}). $$
虽然输入交叉注意力捕获了局部时间结构(即在 50 毫秒块内),但 SSM 通过其隐藏状态将这些信息与历史上下文集成,使 POSSM 能够在局部和全局时间尺度上处理信息。我们使用三种不同的骨干架构进行实验:对角结构状态空间模型(S4D)、GRU 和 Mamba。然而,我们希望指出,这种方法与任何其他类型的循环模型兼容。有关每种骨干架构的具体信息,请参见第 B.2 节。
Output cross-attention and readout
To decode behaviour, we select the $k$ most recent hidden states $\{h^{(t−k+1):(t)}\}$ ($k = 3$ in our experiments), and use a cross-attention module to query them for behavioural predictions. For a given time chunk $t$, we generate $P$ queries, one for each timestamp at which we wish to predict behaviour. Each query encodes the associated timestamp (using RoPE), along with a learnable session embedding that captures latent factors of the recording session. The design of our output module enables flexibility in several ways:
- we can predict multiple outputs per time chunk, enabling a denser and richer supervision signal,
- we are not required to precisely align behaviour to chunk boundaries, and
- we can predict behaviour beyond the current chunk, allowing us to account for lags between neural activity and behavioural action (see Section D.5).
为了对行为进行解码,我们选择最近的 $k$ 个隐藏状态 $\{h^{(t−k+1):(t)}\}$(在我们的实验中为 $k = 3$),并使用交叉注意力模块对它们进行查询以进行行为预测。对于给定的时间块 $t$,我们生成 $P$ 个查询,每个查询对应我们希望预测行为的时间戳。每个查询使用 RoPE 编码相关的时间戳,以及一个可学习的会话嵌入,用于捕获记录会话的潜在因素。我们输出模块的设计在几个方面提供了灵活性:
- 我们可以为每个时间块预测多个输出,从而实现更密集和更丰富的监督信号,
- 我们不需要将行为精确对齐到块边界,以及
- 我们可以预测当前块之外的行为,使我们能够考虑神经活动与行为动作之间的滞后(见第 D.5 节)。
Generalizing to unseen data with pretrained models
Given a pretrained model, we outline two strategies for adapting it to a new set of neural units, with a trade-off between efficiency and decoding accuracy.
给定一个预训练模型,我们概述了两种将其适应于一组新的神经单元的策略,在效率和解码精度之间进行权衡。
Unit identification
To enable efficient generalization to previously unseen neural units, we adopt unit identification (UI), a finetuning strategy enabled by the spike tokenization scheme adopted from POYO. In UI, new neural units can be processed by a model simply by learning new embeddings. Using this approach, we freeze the model weights, initialize new unit and session embeddings, and then train them on the data from the new session while the rest of the model is kept unchanged. This allows us to preserve the neural dynamics learned during pretraining, resulting in an efficient generalization strategy that typically updates less than $1\%$ of the model’s total parameters.
为了实现对先前未见过的神经单元的高效泛化,我们采用了 单元识别(UI),这是一种由 POYO 采用的脉冲标记化方案启用的微调策略。在 UI 中,通过学习新的嵌入,模型可以简单地处理新的神经单元。使用这种方法,我们冻结模型权重,初始化新的单元和会话嵌入,然后在新会话的数据上训练它们,同时保持模型的其余部分不变。这使我们能够保留预训练期间学到的神经动力学,产生一种高效的泛化策略,通常只更新模型总参数的不到 $1\%$。
Full finetuning
While unit identification is an efficient finetuning method, it does not reliably match the performance of models trained end-to-end on individual sessions.
To address this, we also explored full finetuning (FT), a complementary approach which uses a gradual unfreezing strategy.
We begin by only doing UI for some number of epochs before unfreezing the entire model and training end-to-end. This allows us to retain the benefits of pretraining while gradually adapting to the new session.
As shown below, full finetuning consistently outperforms both single-session training and unit identification across all tasks explored, demonstrating effective transfer to new animals, tasks, and remarkably, across species.
虽然单元识别是一种高效的微调方法,但它并不可靠地匹配在单个会话上端到端训练的模型的性能。
为了解决这个问题,我们还探索了 完全微调(FT),这是一种互补的方法,使用渐进解冻策略。
我们首先只进行 UI 一段时间,然后解冻整个模型并进行端到端训练。这使我们能够保留预训练的好处,同时逐步适应新会话。
如下面所示,完全微调在所有探索的任务中始终优于单会话训练和单元识别,展示了对新动物、任务,甚至跨物种的有效转移。
Experiments
We evaluate POSSM across three categories of cortical activity datasets: NHP reaching tasks, human imagined handwriting, and human attempted speech.
我们在三类皮层活动数据集上评估 POSSM:NHP 到达任务、人类想象手写和人类尝试语音。
For the NHP reaching tasks, we highlight the benefits of scale by introducing o-POSSM, a POSSM variant pretrained on multiple datasets.
We compare it to single-session models on held-out sessions with varying similarity with the training data, demonstrating improved decoding accuracy with pretraining.
对于 NHP 到达任务,我们通过引入 o-POSSM(一种在多个数据集上预训练的 POSSM 变体)来突出规模的好处。
我们将其与在具有不同相似性的训练数据的保留会话上的单会话模型进行比较,表明 预训练 提高了解码精度。
Next, we show that o-POSSM achieves powerful downstream decoding performance on a human handwriting task, illustrating the POSSM framework’s capacity for cross-species transfer.
Finally, we demonstrate that POSSM effectively leverages its recurrent architecture to efficiently decode human speech - a long-context task that can become computationally expensive for standard Transformer-based models with quadratic complexity.
In each of these tasks, we see that POSSM consistently matches or outperforms other architectures in a causal evaluation setting, with performance improving as model size and pretraining scale increase.
接下来,我们展示了 o-POSSM 在人类手写任务上实现了强大的下游解码性能,说明了 POSSM 框架跨物种转移的能力。
最后,我们证明了 POSSM 有效地利用其递归架构来高效解码人类语音——这是一项长上下文任务,对于具有二次复杂度的标准基于 Transformer 的模型来说可能变得计算昂贵。
在这些任务中的每一个中,我们看到 POSSM 在因果评估设置中始终匹配或优于其他架构,随着模型规模和预训练规模的增加,性能也在提高。
Task schematics and outputs. (a) Centre-out (CO) task with a manipulandum. (b) Random target (RT) task with a manipulandum. (c) RT task with a touchscreen. (d) Maze task with a touchscreen. (e) Ground truth vs. predicted behaviour outputs from a held-out CO session. (f) Same as (e) but for an RT session. (g) Human handwriting decoding task. (h) Human speech decoding task.
任务示意图和输出。(a) 带有操纵杆的中心外(CO)任务。(b) 带有操纵杆的随机目标(RT)任务。(c) 带有触摸屏的 RT 任务。(d) 带有触摸屏的迷宫任务。(e) 来自保留 CO 会话的真实值与预测行为输出。(f) 与 (e) 相同,但用于 RT 会话。(g) 人类手写解码任务。(h) 人类语音解码任务。
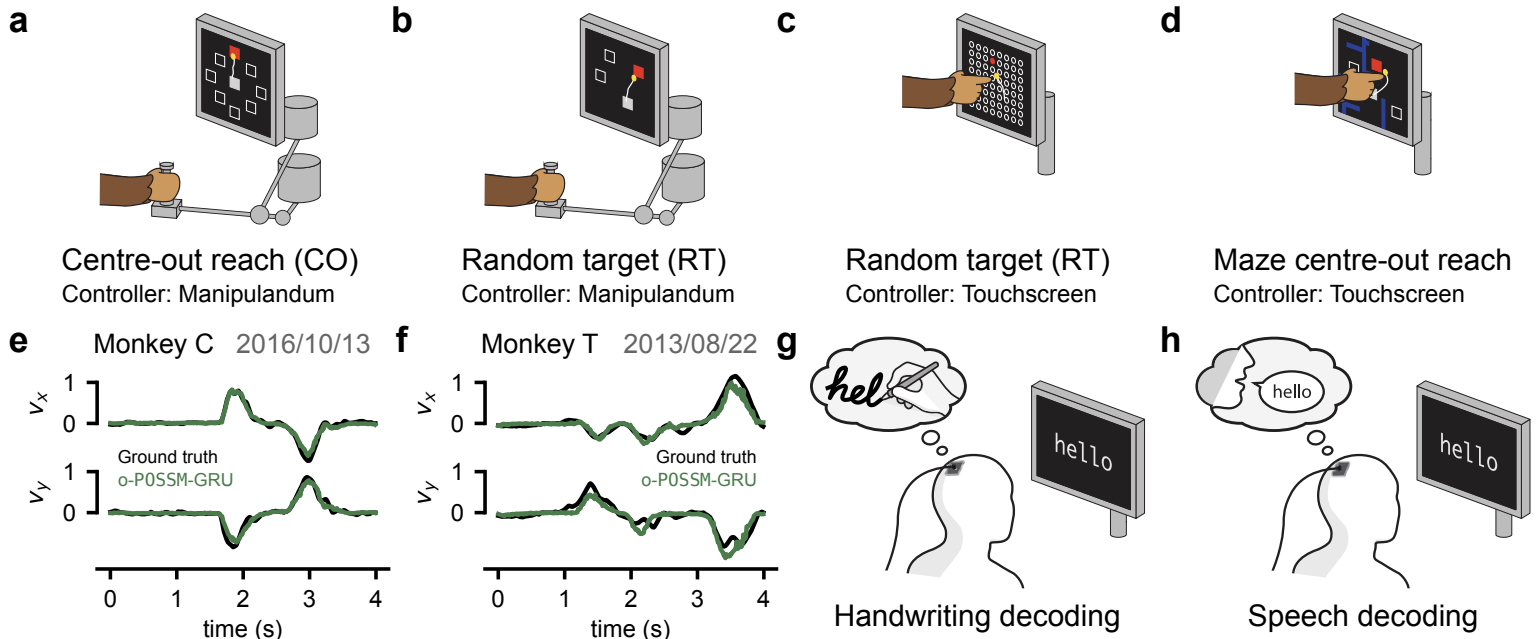
Non-human primate reaching
We first evaluate POSSM on the task of decoding two-dimensional hand velocities in monkeys performing various reaching tasks (shown in Figure 3a-f). Each training sample consists of 1 s of spiking activity paired with the corresponding 2D hand velocity time series over that same interval. This 1 s window is split up into 20 non-overlapping chunks of 50 ms, which are fed sequentially to POSSM (see Section D.1 for results on 20 ms chunks). This streaming setup enables efficient real-time decoding, where only the most recent 50 ms chunk is processed at each step. In sharp contrast, the original POYO model reprocesses an entire 1 s window of activity with each new input, resulting in significantly higher computational cost.
我们首先在猴子执行各种到达任务时解码二维手速度的任务上评估 POSSM(如图 3a-f 所示)。每个训练样本由 1 秒的脉冲活动与该时间间隔内相应的 2D 手速度时间序列配对组成。这个 1 秒窗口被分成 20 个不重叠的 50 毫秒块,依次馈送给 POSSM(有关 20 毫秒块的结果,请参见第 D.1 节)。这种流式设置实现了高效的实时解码,每个步骤只处理最近的 50 毫秒块。与此形成鲜明对比的是,原始 POYO 模型在每个新输入时重新处理整个 1 秒的活动窗口,导致计算成本显著更高。
Experimental Setup
We use a similar experimental setup to POYO. The pretraining dataset includes four NHP reaching datasets collected by different laboratories, covering three types of reaching tasks: centre-out (CO), random target (RT), and Maze.
CO is a highly-structured task involving movements from the centre of the screen to one of eight targets (Figure 3a). Conversely, the RT (Figure 3b-c) and Maze (Figure 3d) tasks are behaviourally more complex, requiring movement to randomly placed targets and navigating through a maze, respectively.
我们使用与 POYO 类似的实验设置。预训练数据集包括由不同实验室收集的四个 NHP 到达数据集,涵盖三种类型的到达任务:中心外(CO)、随机目标(RT) 和迷宫。
CO 是一种高度结构化的任务,涉及从屏幕中心移动到八个目标之一(图 3a)。相反,RT(图 3b-c)和迷宫(图 3d)任务在行为上更复杂,分别需要移动到随机放置的目标和穿越迷宫。
The testing sessions include:
- new sessions from Monkey C which was seen during pretraining,
- new sessions from Monkey T, not seen during pretraining but collected in the same lab as Monkey C, and
- a new session from a dataset unseen during pretraining.
测试会话包括:
- 来自预训练期间看到的猴子 C 的新会话,
- 来自猴子 T 的新会话,在预训练期间未见过,但与猴子 C 在同一实验室收集,以及
- 来自预训练期间未见过的数据集的新会话。
We call our model pretrained on this dataset o-POSSM (see Section B.3 for details).
In total, o-POSSM was trained on 148 sessions comprising more than 670 million spikes from 26,032 neural units recorded across the primary motor (M1), dorsal premotor (PMd), and primary somatosensory (S1) cortices (see Section A for details). We also pretrain two baseline models, NDT-2 and POYO-1. Additionally, we report the results of single-session models trained from scratch on individual sessions. This includes single-session variants of POSSM (across all backbone architectures) and POYO, as well as other baselines such as a multi-layer perceptron (MLP), S4D, GRU, and Mamba.
我们称在此数据集上预训练的模型为 o-POSSM(详情见第 B.3 节)。
总的来说,o-POSSM 在 148 个会话上进行了训练,这些会话包含来自初级运动皮层(M1)、背侧前运动皮层(PMd)和初级躯体感觉皮层(S1)的 26,032 个神经单元记录的超过 6.7 亿个脉冲(详情见第 A 节)。我们还预训练了两个基线模型,NDT-2 和 POYO-1。此外,我们报告了从头开始在单个会话上训练的单会话模型的结果。这包括 POSSM(跨所有骨干架构)和 POYO 的单会话变体,以及其他基线,如多层感知器(MLP)、S4D、GRU 和 Mamba。
Causal evaluation
To simulate real-world decoding scenarios, we adopt a causal evaluation strategy for all models. This is straightforward for POSSM and the recurrent baselines we consider – sequences are split into 50 ms time chunks and fed sequentially to the model.
For the MLP and POYO, we provide a fixed 1 s history of neural activity at each inference timestep, sliding forward in small increments of 50 ms to collect predictions for all behavioural timestamps. For POYO, we only recorded predictions for timestamps in the final 50 ms of each 1 s context window.
为了模拟现实世界的解码场景,我们为所有模型采用了 因果评估策略。这对于我们考虑的 POSSM 和循环基线来说是直接的——序列被分成 50 毫秒的时间块,并依次馈送给模型。
对于 MLP 和 POYO,我们在每个推理时间步提供固定的 1 秒神经活动历史,以 50 毫秒的小增量向前滑动,以收集所有行为时间戳的预测。对于 POYO,我们仅记录每个 1 秒上下文窗口中最后 50 毫秒的时间戳的预测。
During training, the models are presented with contiguous and non-overlapping 1 s sequences, which are not trial-aligned. However, we evaluate our models on entire trials, which are typically much longer than a second.
For example, in sessions from the Perich et al. dataset, trials in the validation and testing sets are at least $3\times$ and up to $5\times$ longer than the training sequences. This means that a recurrent model must generalize to sequences longer than the ones seen during training.
在训练期间,模型呈现连续且不重叠的 1 秒序列,这些序列未对齐试验。然而,我们在整个试验上评估我们的模型,这些试验通常比一秒钟长得多。
例如,在 Perich 等人的数据集中,验证和测试集中的试验至少比训练序列长 $3\times$,最多长 $5\times$。这意味着循环模型必须推广到比训练期间看到的序列更长的序列。
Transfer to new sessions
In Table 1, we evaluate the transferability of our pretrained models to new sessions, animals, and datasets, and compare them to single-session models. When trained on a single session, POSSM is on par with or outperforms POYO on most sessions. When using pretrained models, o-POSSM-S4D shows the best overall performance. Finally, we observe that FT is noticeably better than UI when transferring to new animals or datasets. However, UI performs on par with or better than several single-session models, and requires far fewer parameters to be trained.
在表 1 中,我们评估了预训练模型向新会话、动物和数据集的可转移性,并将其与单会话模型进行比较。当在单个会话上训练时,POSSM 在大多数会话中与 POYO 相当或优于 POYO。使用预训练模型时,o-POSSM-S4D 显示出最佳的整体性能。最后,我们观察到,在转移到新动物或数据集时,FT 明显优于 UI。然而,UI 的表现与几个单会话模型相当或更好,并且需要训练的参数远少于 FT。
Sample and training compute efficiency
A key motivation behind training neural decoders on large, heterogeneous datasets is to enable efficient transfer to new individuals, tasks, or species with minimal finetuning. To this end, we evaluated the effectiveness of our finetuning strategies through few-shot experiments. Our results, shown in Figure 4a-b, demonstrate that o-POSSM outperforms single-session models trained from scratch in low-data regimes. Notably, we observe that pretraining results in a considerable initial boost in performance when adapting to a new session, even when only unit and session embeddings are updated. In some cases, single-session models fail to match the performance of a finetuned model, even after extensive training. Overall, our results are in line with observations from Azabou et al., supporting the idea that with the right tokenization and data aggregation schemes, pretrained models can amortize both data and training costs, leading to efficient adaptation to downstream applications.
训练神经解码器的一个关键动机是能够通过最小的微调实现对新个体、任务或物种的高效转移。为此,我们通过少量实验评估了微调策略的有效性。我们的结果如图 4a-b 所示,表明 o-POSSM 在低数据环境下优于从头开始训练的单会话模型。值得注意的是,我们观察到,在适应新会话时,预训练即使仅更新单元和会话嵌入,也会带来显著的初始性能提升。在某些情况下,单会话模型即使经过大量训练也无法匹配微调模型的性能。总体而言,我们的结果与 Azabou 等人的观察结果一致,支持这样一种观点:通过正确的标记化和数据聚合方案,预训练模型可以摊销数据和训练成本,从而实现对下游应用的高效适应。
Sample and compute efficiency benchmarking. (a) Results on a held-out CO session from Monkey C. On the left, we show the sample efficiency of adapting a pretrained model versus training from scratch. On the right, we compare training compute efficiency between these two approaches. (b) Same as (a) but for a held-out RT session from Monkey T – a new subject not seen during training. (c) Comparing model performance and compute efficiency to baseline models. Inference times are computed on a workstation-class GPU (NVIDIA RTX8000). For all these results, we used a GRU backbone for POSSM.
样本和计算效率基准测试。(a) 来自猴子 C 的保留 CO 会话的结果。在左侧,我们展示了预训练模型与从头开始训练的样本效率。在右侧,我们比较了这两种方法之间的训练计算效率。(b) 与 (a) 相同,但用于来自猴子 T 的保留 RT 会话——一个在训练期间未见过的新受试者。(c) 将模型性能和计算效率与基线模型进行比较。推理时间是在工作站级 GPU(NVIDIA RTX8000)上计算的。对于所有这些结果,我们为 POSSM 使用了 GRU 骨干。
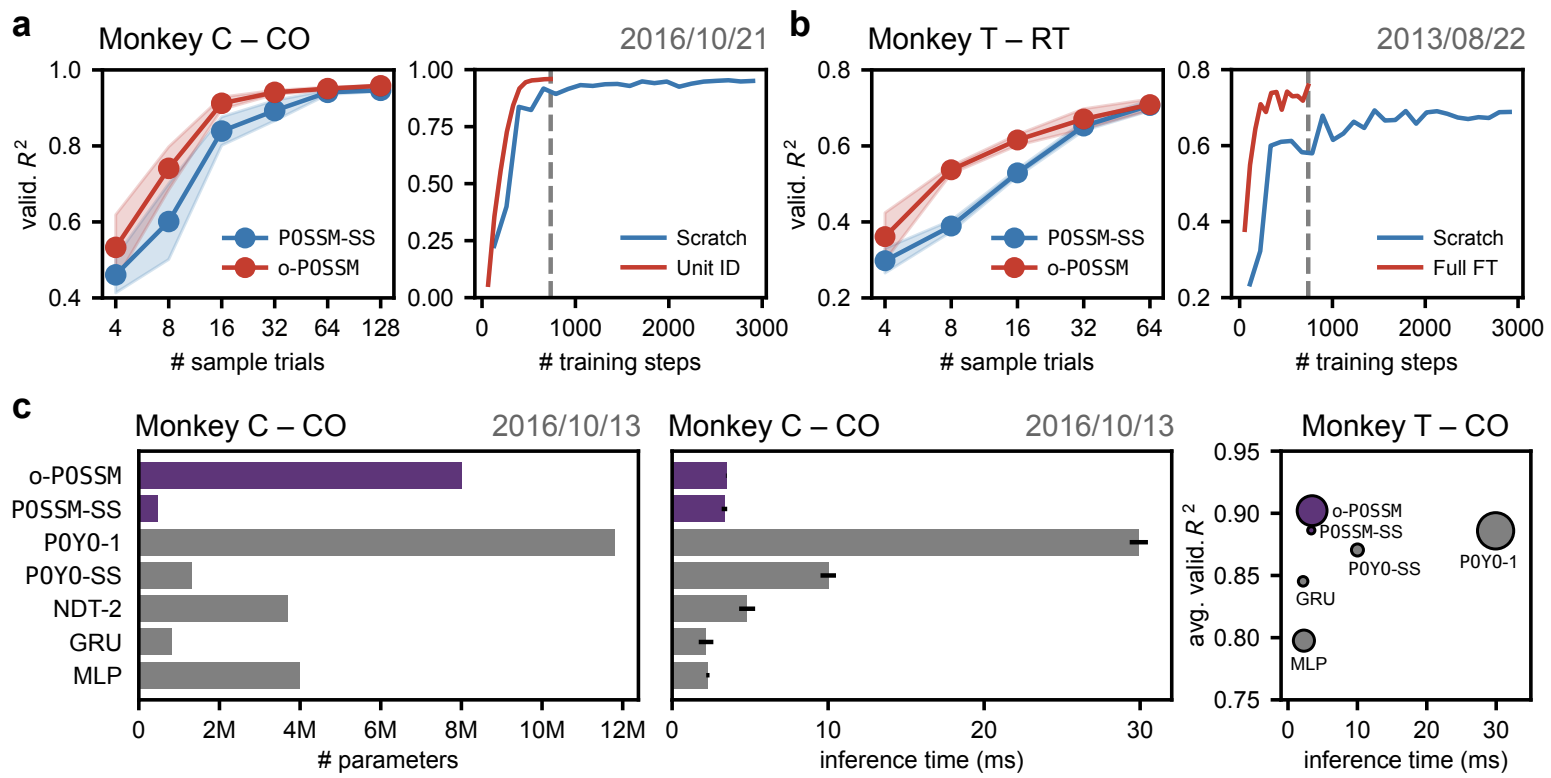
Inference efficiency
In addition to being efficient to train and finetune, we also evaluated whether POSSM is efficient at inference time. In Figure 4c, we report parameter counts and inference time per time chunk on a workstation-class GPU (NVIDIA RTX8000) for POSSM and several state-of-the-art neural decoders.
除了训练和微调效率高之外,我们还评估了 POSSM 在推理时是否高效。在图 4c 中,我们报告了工作站级 GPU(NVIDIA RTX8000)上 POSSM 和几种最先进神经解码器的参数计数和每个时间块的推理时间。
We find that our single and multi-session models achieve inference speeds that are comparable to lightweight models like GRUs and MLPs and significantly lower than complex models like NDT-2 and POYO, while retaining competitive performance.
Single-session POSSM models (POSSMSS) contained the fewest parameters, and even o-POSSM, with about 8M parameters, maintained low latency. These results held in a CPU environment (AMD EPYC 7502 32-Core) as well, with POSSMSS and o-POSSM achieving inference speeds of $\sim 2.44\text{ ms/chunk}$ and $\sim 5.65\text{ ms/chunk}$, respectively.
Overall, our results show that POSSM’s inference time is well within the optimal real-time BCI decoding latency of $\leq 10\text{ ms}$, making it a viable option for real-time BCI decoding applications.
我们发现,我们的单会话和多会话模型实现的推理速度与轻量级模型(如 GRU 和 MLP)相当,并且显著低于复杂模型(如 NDT-2 和 POYO),同时保持竞争性能。
单会话 POSSM 模型(POSSMSS)包含最少的参数,即使是具有约 800 万参数的 o-POSSM 也保持了低延迟。这些结果在 CPU 环境(AMD EPYC 7502 32-Core)中也成立,POSSMSS 和 o-POSSM 分别实现了 $\sim 2.44\text{ ms/chunk}$ 和 $\sim 5.65\text{ ms/chunk}$ 的推理速度。
总体而言,我们的结果表明 POSSM 的推理时间远低于最佳实时 BCI 解码延迟 $\leq 10\text{ ms}$,使其成为实时 BCI 解码应用的可行选择。
Human handwriting
Next, we evaluated POSSM on a human handwriting dataset. This dataset contains 11 sessions recorded from a single individual, where they imagined writing individual characters and drawing straight lines (Figure 3g). Spike counts from multi-unit threshold crossings were recorded from two 96-channel microelectrode arrays implanted in the participant’s motor cortex. These were then binned at 10 ms intervals. The models were trained to classify the intended characters or lines based on this neural activity. For evaluation, we used 9 sessions, each containing 10 trials per character class. Each individual trial consisted of a 1.6 s time-window centred around the “go” cue.
接下来,我们在一个人类手写数据集上评估了 POSSM。该数据集包含从单个个体记录的 11 个会话,其中他们想象写单个字符和绘制直线(图 3g)。来自参与者运动皮层中植入的两个 96 通道微电极阵列的多单元阈值交叉的脉冲计数被记录下来。然后,这些数据以 10 毫秒间隔进行分箱。模型被训练用来根据这些神经活动对预期的字符或线条进行分类。为了评估,我们使用了 9 个会话,每个会话包含每个字符类别的 10 次试验。每个单独的试验由围绕“开始”提示的 1.6 秒时间窗口组成。
Results
We compared POSSM with five baselines: the previously published statistical method PCA-KNN, GRU, S4D, Mamba and POYO. For POSSM and all baselines except POYO, we adopted the causal evaluation strategy described in Section 3.1, training on 1 s intervals and evaluating on full 1.6 s trials. For POYO, we followed the evaluation scheme from the original paper, using fixed 1 s context windows for both training and testing.
我们将 POSSM 与五个基线进行了比较:先前发布的统计方法 PCA-KNN、GRU、S4D、Mamba 和 POYO。对于 POSSM 和除 POYO 之外的所有基线,我们采用了第 3.1 节中描述的因果评估策略,在 1 秒间隔上进行训练,并在完整的 1.6 秒试验上进行评估。对于 POYO,我们遵循了原始论文中的评估方案,使用固定的 1 秒上下文窗口进行训练和测试。
As shown in Table 2, POSSM-GRU outperforms all baseline models when trained from scratch on the 9 sessions. Remarkably, finetuning o-POSSM, which was only pretrained on NHP data, led to significant performance gains: $2\%$ for POSSM-GRU and more than $5\%$ for both POSSM-S4D and POSSM-Mamba. All of the POSSM models achieve state-ofthe-art performance on this task, with the finetuned o-POSSM variants considerably outperforming the baseline PCA-KNN, achieving test accuracies that are about $16\%$ greater.
如表 2 所示,POSSM-GRU 在从头开始在 9 个会话上训练时优于所有基线模型。值得注意的是,对仅在 NHP 数据上预训练的 o-POSSM 进行微调带来了显著的性能提升:POSSM-GRU 提升了 $2\%$,而 POSSM-S4D 和 POSSM-Mamba 则提升了超过 $5\%$。所有 POSSM 模型在此任务上都实现了最先进的性能,经过微调的 o-POSSM 变体显著优于基线 PCA-KNN,实现了约 $16\%$ 更高的测试准确率。
These results establish a critical finding: neural dynamics learned from NHP datasets can generalize across different species performing distinct tasks. This is especially impactful given the challenges of collecting large-scale human electrophysiology datasets, suggesting that the abundance of NHP datasets can be used to effectively improve human BCI decoders.
这些结果确立了一个关键发现:从 NHP 数据集中学到的神经动力学可以跨不同物种执行不同任务进行泛化。鉴于收集大规模人类电生理数据集的挑战,这一点尤其具有影响力,表明丰富的 NHP 数据集可以用来有效地改善人类 BCI 解码器。
Human speech
Finally, we evaluated POSSM on the task of human speech decoding. Unlike the reaching and handwriting tasks, which involved fixed-length context windows, speech decoding involves modelling variable-length phoneme sequences that depend on both the length of the sentence and the individual’s speaking pace. We used a public dataset consisting of 24 sessions in which a human participant with speech deficits attempted to speak sentences that appeared on a screen (Figure 3h).
最后,我们在人类语音解码任务上评估了 POSSM。与涉及固定长度上下文窗口的到达和手写任务不同,语音解码涉及建模可变长度的音素序列,这些序列取决于句子的长度和个体的说话速度。我们使用了一个公共数据集,其中包含 24 个会话,在这些会话中,一位有语言障碍的人类参与者试图说出屏幕上出现的句子(图 3h)。
Neural activity was recorded from four 64-channel microelectrode arrays that covered the premotor cortex and Broca’s area. Multi-unit spiking activity was extracted and binned at a resolution of 20 ms, where the length of each trial ranged from 2 to 18 seconds. This poses a problem for Transformers like POYO that were designed for 1 s contexts, as the quadratic complexity of the attention mechanism would result in a substantial increase in computation for longer sentences.
神经活动是从覆盖前运动皮层和 Broca 区的四个 64 通道微电极阵列中记录的。多单元脉冲活动被提取并以 20 毫秒的分辨率进行分箱,每次试验的长度从 2 秒到 18 秒不等。这对像 POYO 这样的为 1 秒上下文设计的 Transformer 架构来说是一个问题,因为注意力机制的二次复杂度会导致对于较长句子计算量的大幅增加。
Although both uni- and bi-directional GRUs were used in the original study, we focused primarily on the causal, uni-directional case, as it is more relevant for real-time decoding. In line with Willett et al., we z-scored the neural data and added Gaussian noise as an augmentation. We used the phoneme error rate (PER) as our primary evaluation metric. While prior work has successfully incorporated language models to leverage textual priors, we leave this as a future research direction, instead focusing here on POSSM’s capabilities.
尽管原始研究中使用了单向和双向 GRU,但我们主要关注因果的单向情况,因为它与实时解码更相关。与 Willett 等人一致,我们对神经数据进行了 z-score 标准化,并添加了高斯噪声作为增强。我们使用 音素错误率(PER) 作为主要评估指标。虽然先前的工作已经成功地结合了语言模型来利用文本先验知识,但我们将其作为未来的研究方向,在这里专注于 POSSM 的能力。
Previous work has shown that Transformer-based decoders perform poorly on this task compared to GRU baselines. Here, we demonstrate the value of instead integrating attention with a recurrent model by using POSSM, specifically with a GRU backbone.
先前的工作表明,与 GRU 基线相比,基于 Transformer 的解码器在此任务上的表现较差。在这里,我们通过使用 POSSM(特别是带有 GRU 骨干)来展示将注意力与循环模型集成的价值。
However, since only normalized spike counts (and not spike times) were available in the dataset, we were unable to use the POYO-style tokenization as-is. Instead, we treated each multi-unit channel as a neural unit and encoded the normalized spike counts with value embeddings. Furthermore, we replaced the output cross-attention module with a 1D strided convolution layer to control the length of the output sequence. This approach significantly reduced the number of model parameters compared to the GRU baseline, which used strided sliding windows of neural activity as inputs instead.
然而,由于数据集中仅提供了归一化的脉冲计数(而不是脉冲时间),我们无法按原样使用 POYO 风格的标记化。相反,我们将每个多单元通道视为一个神经单元,并使用值嵌入对归一化的脉冲计数进行编码。此外,我们用 1D 步幅卷积层替换了输出交叉注意力模块,以控制输出序列的长度。这种方法显著减少了与 GRU 基线相比的模型参数数量,后者使用神经活动的步幅滑动窗口作为输入。
We found that a two-phase training procedure yielded the best results. In the first phase, we trained the input cross-attention module along with the latent and unit embeddings by reconstructing the spike counts at each individual time bin. In the second phase, we trained the entire POSSM model on the target phoneme sequences using Connectionist Temporal Classification (CTC) loss.
我们发现,两阶段的训练程序产生了最佳结果。在第一阶段,我们通过重建每个单独时间箱的脉冲计数来训练输入交叉注意力模块以及潜在和单元嵌入。在第二阶段,我们使用连接时序分类(CTC)损失对整个 POSSM 模型进行目标音素序列的训练。
Results
POSSM achieved a significant improvement over all other baselines, as shown in Table 3. Notably, POSSM maintained comparable performance even without the Gaussian noise augmentation, while the performance of the baseline GRU was greatly impaired under the same conditions. Furthermore, we show in preliminary experiments with multiple input modalities (i.e., both spike counts and spiking-band powers) that POSSM yet again outperforms the baseline. These results illustrate the robustness of the POSSM architecture to variability in data preprocessing and its flexibility with respect to input modalities, further strengthening its case as a feasible real-world decoder.
POSSM 在所有其他基线之上实现了显著的改进,如表 3 所示。值得注意的是,即使没有高斯噪声增强,POSSM 仍然保持了相当的性能,而在相同条件下,基线 GRU 的性能大大受损。此外,我们在使用多种输入模态(即脉冲计数和脉冲带功率)的初步实验中表明,POSSM 再次优于基线。这些结果说明了 POSSM 架构对数据预处理变异性的鲁棒性及其对输入模态的灵活性,进一步加强了其作为可行的现实世界解码器的案例。
Related Work
Neural decoding
Neural decoding for continuous tasks such as motor control in BCIs was traditionally accomplished using statistical models such as the Kalman filter.
While these models are reliable and perform well for specific users and sessions, they require careful adaptation to generalize to new days, users, and even tasks.
Such adaptation is typically accomplished using model fitting approaches to estimate the Kalman filter parameters, a process that requires considerable new training data for each application.
Traditional approaches to multi-session neural decoding often consist of learning the decoder’s parameters on a specific day or session (e.g., the first day), followed by learning models to align the neural activity on subsequent days to facilitate generalization.
神经解码用于 BCI 中的连续任务(如运动控制)传统上是通过统计模型(如卡尔曼滤波器)来完成的。
虽然这些模型可靠且在特定用户和会话中表现良好,但它们需要仔细调整以实现对新日期、用户甚至任务的泛化。
这种调整通常是通过模型拟合方法来估计卡尔曼滤波器参数来完成的,这一过程需要为每个应用提供大量新的训练数据。
传统的多会话神经解码方法通常包括在特定日期或会话(例如第一天)上学习解码器的参数,然后学习模型以对齐后续日期的神经活动以促进泛化。
Given the recent availability of large, public neural recordings datasets, modern neural decoding approaches have attempted to leverage advances in large-scale deep learning to build data-driven BCI decoders.
For example, in the context of decoders for neuronal spiking activity, NDT jointly embeds spikes from a neural population into a single token per time bin, spatiotemporal NDT (STNDT) separately tokenizes across units and time and learns a joint representation across these two contexts, NDT-2 tokenizes spatiotemporal patches of neural data akin to a ViT, and POYO eschews bin-based tokenization, opting to tokenize individual spikes and using a PerceiverIO Transformer backbone to query behaviours from within specific context windows.
鉴于最近大型公共神经记录数据集的可用性,现代神经解码方法试图利用大规模深度学习的进步来构建数据驱动的 BCI 解码器。
例如,在神经元脉冲活动解码器的背景下,NDT 将神经群体的脉冲嵌入到每个时间箱中的单个标记中,时空 NDT(STNDT)在单元和时间上分别进行标记化,并学习这两个上下文之间的联合表示,NDT-2 类似于 ViT 对神经数据的时空补丁进行标记化,而 POYO 放弃了基于箱的标记化,选择对单个脉冲进行标记化,并使用 PerceiverIO Transformer 骨干从特定上下文窗口中查询行为。
While several of these works excel at neural decoding, they do not focus on enabling generalizable, online decoding in spike-based BCIs and closed-loop protocols.
The BRAND platform enables the deployment of specialized deep learning models in real-time closed-loop brain-computer interface experiments with invasive recordings, demonstrating suitable low-latency neural decoding in other models such as LFADS.
Finally, we note other ML methods for neural data processing other than direct behaviour decoding. Contrastive learning methods that aim to identify joint latent variables between neural activity and behaviour can be useful for decoding but work is needed for online use. Diffusion-based approaches are promising for jointly forecasting neural activity and behaviour, but again are not readily suited for online use.
虽然这些工作中的几个在神经解码方面表现出色,但它们并不专注于实现可泛化的在线解码,以用于基于脉冲的 BCI 和闭环协议。
BRAND 平台使得在具有侵入性记录的实时闭环脑机接口实验中部署专门的深度学习模型成为可能,在 LFADS 等其他模型中展示了适当的低延迟神经解码。
最后,我们注意到除了直接行为解码之外,还有其他用于神经数据处理的 ML 方法。旨在识别神经活动和行为之间联合潜变量的对比学习方法对于解码可能有用,但需要进行在线使用的工作。基于扩散的方法有望联合预测神经活动和行为,但同样不适合在线使用。
Hybrid attention-recurrence models
Several works have attempted to combine self- and cross-attention layers with recurrent architectures, usually with the goal of combining the expressivity of attention over shorter timescales with the long-term context modelling abilities of recurrent models such as structured SSMs.
一些工作试图将自注意力和交叉注意力层与循环架构相结合,通常目的是结合注意力在较短时间尺度上的表现力与循环模型(如结构化 SSM)在长期上下文建模方面的能力。
While traditional SSMs have been used for several neuroscience applications, modern SSMs and hybrid models remain underexplored in the field.
Didolkar et al. propose an architecture comprising Transformer blocks which process information at faster, shorter timescales while a recurrent backbone integrates information from these blocks over longer timescales for long-term contextual modeling.
A similar approach is the Block-Recurrent Transformer, wherein a recurrent cell operates on a block of tokens in parallel, thus propagating a block of state vectors through timesteps. Pilault et al. propose the Block-State Transformer architecture, which introduces a layer consisting of an SSM to process long input sequences, the outputs of which are sent in blocks to several Transformers that process them in parallel to produce output tokens. Furthermore, several recent works on high-throughput language modelling have leveraged hybrid models, where self-attention layers are replaced with SSM blocks to take advantage of their subquadratic computational complexity.
虽然传统的 SSM 已被用于多个神经科学应用,但现代 SSM 和混合模型在该领域仍然未被充分探索。
Didolkar 等人提出了一种架构,该架构包括 Transformer 块,这些块在更快、更短的时间尺度上处理信息,而循环骨干则整合来自这些块的信息以进行长期上下文建模。
类似的方法是块循环 Transformer,其中循环单元并行地在一块标记上运行,从而通过时间步传播一块状态向量。Pilault 等人提出了块状态 Transformer 架构,该架构引入了一层包含 SSM 的层来处理长输入序列,其输出以块的形式发送到几个 Transformer,这些 Transformer 并行处理它们以生成输出标记。此外,最近关于高吞吐量语言建模的几项工作利用了混合模型,其中自注意力层被 SSM 块替换,以利用其亚二次计算复杂度。
Discussion
Summary
We introduced POSSM, a scalable and generalizable hybrid architecture that pairs spike tokenization and input-output cross-attention with SSMs. This architecture enables efficient online decoding applications, achieving state-of-the-art performance for several neural decoding tasks while having fewer parameters and faster inference compared to fully Transformer-based approaches. Our model achieves high performance with millisecond-scale inference times on standard workstations, even without GPUs, making it suitable for real-time deployment in clinical settings.
我们介绍了 POSSM,这是一种可扩展且可泛化的混合架构,将脉冲标记化和输入输出交叉注意力与 SSM 配对。该架构实现了高效的在线解码应用,在多个神经解码任务中实现了最先进的性能,同时与完全基于 Transformer 的方法相比,参数更少且推理更快。我们的模型在标准工作站上实现了毫秒级的高性能推理时间,即使没有 GPU,也适合在临床环境中进行实时部署。
A key contribution of this work is demonstrating, to our knowledge, the first successful cross-species transfer of learned neural dynamics for a deep learning-based decoder – from NHP motor cortex to human clinical data (see [11, 62] for related efforts). This outlines a solution to a major clinical hurdle, where obtaining sufficient data for large-scale modelling is challenging or impossible in patient populations. We demonstrate that we can leverage the large corpus of existing non-human experimental data to improve personalized clinical outcomes by finetuning pretrained models.
这项工作的一个关键贡献是展示了我们所知的第一个成功的跨物种转移学习神经动力学的深度学习解码器——从 NHP 运动皮层到人类临床数据(有关相关工作,请参见 [11, 62])。这为一个主要的临床障碍提供了解决方案,在患者群体中获得足够的大规模建模数据是具有挑战性或不可能的。我们展示了如何利用现有的大量非人类实验数据,通过微调预训练模型来改善个性化临床结果。
Future directions and applications
The POSSM architecture is applied here for motor neural decoding, but it can be adapted to achieve a variety of outcomes. Our current model focuses on processing spiking data from implanted arrays in the motor cortex of monkeys and human clinical trial participants. However, our hybrid architecture is flexible and could readily accommodate data of other neural data modalities through a variety of proven tokenization schemes (e.g., Calcium imaging, EEG). While in the present work we focus on decoding of behavioural timestamps immediately following our input time chunks, our hybrid architecture is well-suited towards forecasting over longer timescales. Further, in the future we plan to explore the ability of POSSM to learn and generalize across different regions beyond the motor cortex.
POSSM 架构在这里应用于运动神经解码,但它可以适应以实现各种结果。我们当前的模型专注于处理来自猴子和人类临床试验参与者运动皮层中植入阵列的脉冲数据。然而,我们的混合架构具有灵活性,可以通过各种经过验证的标记化方案轻松适应其他神经数据模态的数据(例如,钙成像、EEG)。虽然在当前工作中我们专注于解码紧随输入时间块之后的行为时间戳,但我们的混合架构非常适合于更长时间尺度的预测。此外,未来我们计划探索 POSSM 学习和泛化到运动皮层以外不同区域的能力。
Ultimately, we envision POSSM as a first step towards a fast, generalizable neural foundation model for various neural interfacing tasks, with downstream applications such as clinical diagnostics and the development of smart, closed-loop neuromodulation techniques that link predicted states to optimized neural stimulators (e.g., [4, 5]).
Future steps include multimodal pretraining and decoding as well as a principled self-supervised pretraining scheme. By enabling efficient inference and flexible generalization through transfer learning, POSSM marks a new direction for general-purpose neural decoders with real-world practicality.
最终,我们将 POSSM 视为各种神经接口任务的快速、可泛化神经基础模型的第一步,下游应用包括临床诊断和智能闭环神经调节技术的发展,将预测状态与优化的神经刺激器(例如,[4, 5])联系起来。
未来的步骤包括多模态预训练和解码以及有原则的自监督预训练方案。通过通过迁移学习实现高效推理和灵活泛化,POSSM 标志着具有现实世界实用性的通用神经解码器的新方向。
Broader Impact
This research could potentially contribute to the development of neural decoders that are not only accurate but also amenable to deployment in online systems, such as those found in neuroprosthetics and other brain-computer interfaces. In addition to POSSM’s general performance, it reduces the need for extensive individual calibration due to the pretraining/finetuning scheme. Additionally, the crossspecies transfer results on the handwriting task suggest that patients with limited availability of data could benefit from models pretrained with larger datasets from different species. While the potential downstream applications of POSSM are exciting, it is important to consider the ethical concerns that exist for any medical technology, including but not limited to data privacy and humane data collection from animals. Strict testing should be implemented before deployment in any human-related setting.
这项研究有可能有助于开发不仅准确而且适合部署在在线系统中的神经解码器,例如神经假体和其他脑机接口中。除了 POSSM 的整体性能外,由于预训练/微调方案,它减少了对广泛个人校准的需求。此外,手写任务上的跨物种转移结果表明,数据可用性有限的患者可以从使用来自不同物种的大型数据集预训练的模型中受益。虽然 POSSM 的潜在下游应用令人兴奋,但重要的是要考虑任何医疗技术存在的伦理问题,包括但不限于数据隐私和对动物的人道数据收集。在任何与人类相关的环境中部署之前,都应实施严格的测试。