
Abstract
Designing processors for implantable closed-loop neuromodulation systems presents a formidable challenge owing to the constrained operational environment, which requires low latency and high energy efficacy. Previous benchmarks have provided limited insights into power consumption and latency. However, this study introduces algorithmic metrics that capture the potential and limitations of neural decoders for closed-loop intra-cortical brain–computer interfaces in the context of energy and hardware constraints. This study benchmarks common decoding methods for predicting a primate’s finger kinematics from the motor cortex and explores their suitability for low latency and high energy efficient neural decoding. The study found that ANN-based decoders provide superior decoding accuracy, requiring high latency and many operations to effectively decode neural signals. Spiking neural networks (SNNs) have emerged as a solution, bridging this gap by achieving competitive decoding performance within sub-10 ms while utilizing a fraction of computational resources. These distinctive advantages of neuromorphic SNNs make them highly suitable for the challenging closed-loop neural modulation environment. Their capacity to balance decoding accuracy and operational efficiency offers immense potential in reshaping the landscape of neural decoders, fostering greater understanding, and opening new frontiers in closed-loop intra-cortical human-machine interaction.
为可植入闭环神经调节系统设计处理器是一项艰巨的挑战,因为其受限的操作环境需要低延迟和高能效。以往的基准测试对功耗和延迟提供了有限的见解。然而,本研究引入了算法指标,捕捉了神经解码器在能量和硬件约束下用于闭环皮层内脑机接口的潜力和局限性。本研究基准测试了常见的解码方法,以预测灵长类动物运动皮层的手指运动学,并探讨了它们在低延迟和高能效神经解码方面的适用性。研究发现,基于人工神经网络(ANN)的解码器提供了更优的解码精度,但需要高延迟和大量运算才能有效解码神经信号。脉冲神经网络(SNNs)已成为一种解决方案,通过在10毫秒以下实现具有竞争力的解码性能,同时利用极少的计算资源,弥合了这一差距。神经形态 SNNs 的这些独特优势使其非常适合具有挑战性的闭环神经调节环境。它们在平衡解码精度和操作效率方面的能力为重塑神经解码器的格局提供了巨大的潜力,促进了更深入的理解,并为闭环皮层内人机交互开辟了新的前沿。
Introduction
Brain–computer interfaces (BCIs) have revolutionized the fields of neuroscience and medicine by enabling individuals with disabilities to interact with external devices and restore lost sensory, motor, or cognitive functions. Intra-cortical BCIs (iBCIs), a type of invasive BCI that involves placing electrodes directly into the cortex of the brain, have great potential for closed-loop neuromodulation (CLN). CLN alters neural activity using personalized and responsive therapeutic electrical neural modulation based on the subject’s neural activity. CLN has higher efficacy, and lower risk of side effects than fixed stimulation, that is open-loop neuromodulation as shown in figure 1. CLN requires neural decoders that interpret neural activity, such that BCI can provide real-time feedback stimulation or control external devices based on the subject’s neural activity.
**脑机接口(BCI)通过使残疾人能够与外部设备交互并恢复丧失的感觉、运动或认知功能,彻底改变了神经科学和医学领域。皮层内脑机接口(iBCI)是一种侵入性 BCI,涉及将电极直接放置在大脑皮层中,具有闭环神经调节(CLN)**的巨大潜力。CLN 使用基于受试者神经活动的个性化和响应性治疗性电神经调节来改变神经活动。与固定刺激(即开环神经调节)相比,CLN 具有更高的疗效和更低的副作用风险,如图 1 所示。CLN 需要解释神经活动的神经解码器,以便 BCI 能够根据受试者的神经活动提供实时反馈刺激或控制外部设备。
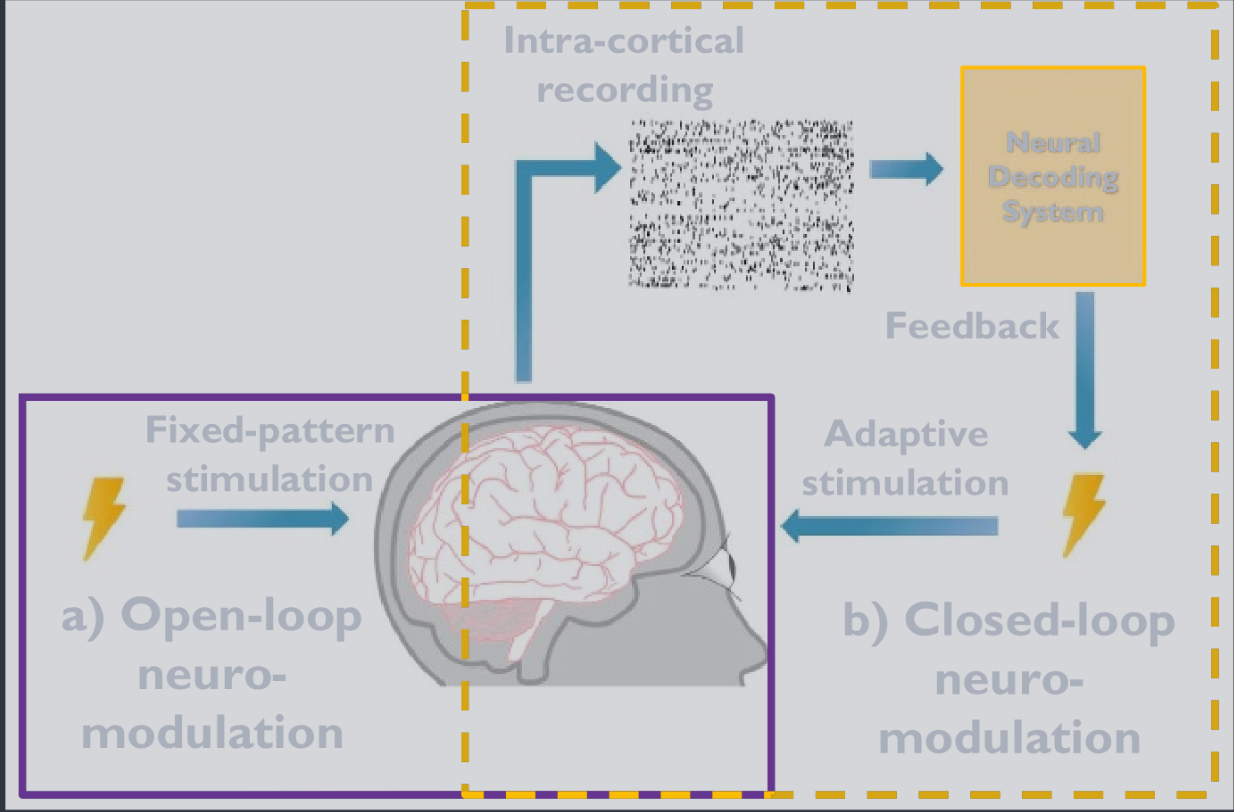
Paradigm of a closed-loop and open-loop neuromodulations. (a) During open-loop neuromodulation, the subject receives predefined stimulation. (b) During closed-loop neuromodulation (CLN), the subject receives adaptive stimulation based on the recorded and decoded neural activities. CLN enables individualized, responsive therapeutic treatment improving the effectiveness of the treatment and reducing side effects.
闭环和开环神经调节的范例。(a) 在开环神经调节期间,受试者接受预定义的刺激。(b) 在闭环神经调节 (CLN) 期间,受试者根据记录和解码的神经活动接收自适应刺激。CLN 实现了个性化、响应性的治疗,提高了治疗效果并减少了副作用。
Designing iBCIs for CLN is challenging because of the highly resource-constrained environment of the implants. Even a slight temperature increase of one degree can cause damage to neural cells. Moreover, a decoding time of a few milliseconds is required for CLN aimed at inter-areal interactions. This requires the development of energy-efficient and low-latency neural decoders that can overcome the constraints of low latency and energy consumption.
为 CLN 设计 iBCI 具有挑战性,因为植入物的资源受限环境非常严重。即使温度略微升高一度也会对神经细胞造成损害。此外,CLN 旨在实现区域间交互,需要几毫秒的解码时间。这需要开发能够克服低延迟和能耗限制的高能效、低延迟神经解码器。
Benchmarking neural decoders for online in vivo iBCIs is crucial to ensure their optimal performance within the resource-constrained environment of implantable systems. By evaluating various decoders based on their fidelity, latency, and power consumption, researchers can identify the most suitable options that satisfy clinical safety requirements and ensure effective real-time operation, ultimately improving the efficacy of CLN.
在体内 iBCI 在线基准测试神经解码器对于确保其在可植入系统的资源受限环境中的最佳性能至关重要。通过根据保真度、延迟和功耗评估各种解码器,研究人员可以确定满足临床安全要求并确保有效实时操作的最合适选项,从而最终提高 CLN 的疗效。
Traditional benchmarks predominantly emphasize the accuracy and fidelity aspects of decoding methods. A recent addition, NeuroBench, expanded this focus to assess algorithm-hardware co-optimization, incorporating fidelity, efficiency, and performance metrics. While NeuroBench is well-suited for evaluating the operational cost of neural decoders, its algorithmic benchmark provides limited insights into power and latency, primarily relying on the effective operational cost as a proxy for hardware metrics. This paper, presents methods to extrapolate algorithmic-to-hardware metrics, addressing the gap encompassing all the essential constraints required to evaluate and compare the suitability of neural decoders for iBCIs in the context of CLN. Any benchmark designed to compare neural decoders for iBCI within the context of CLN must consider the co-optimization between hardware and software. Only then can we benchmark effectively and accurately evaluate power consumption, latency, and the fidelity of neural decoders, providing a holistic assessment of decoder suitability for real-time, low-energy applications.
传统基准测试主要强调解码方法的准确性和保真度方面。最近新增的 NeuroBench 扩展了这一重点,以评估算法-硬件协同优化,结合了保真度、效率和性能指标。虽然 NeuroBench 非常适合评估神经解码器的操作成本,但其算法基准对功率和延迟提供的见解有限,主要依赖于有效操作成本作为硬件指标的代理。本文提出了将算法指标外推到硬件指标的方法,解决了评估和比较神经解码器在 CLN 背景下用于 iBCI 适用性所需的所有基本约束之间的差距。任何旨在比较 CLN 背景下 iBCI 神经解码器的基准都必须考虑硬件和软件之间的协同优化。只有这样,我们才能有效地基准测试并准确评估神经解码器的功耗、延迟和保真度,为实时、低能耗应用提供全面的解码器适用性评估。
This paper will introduce metrics that researchers can use to avoid the complex co-optimization process by evaluating neural decoders algorithmically while incorporating hardware considerations. Section 3 presents metrics designed to suit the energy and hardware-constrained environment of iBCIs suitable for CLN. Section 4 introduces six neural decoders benchmarks their ability to predict a primate’s finger movements. Finally, future directions and implications of this research will be discussed.
本文将介绍研究人员可以使用的指标,通过在考虑硬件的同时对神经解码器进行算法评估,从而避免复杂的协同优化过程。第 3 节介绍了旨在适应适用于 CLN 的 iBCI 的能源和硬件受限环境的指标。第 4 节介绍了六种神经解码器基准及其预测灵长类动物手指运动的能力。最后,将讨论该研究的未来方向和影响。
Background
Intra-cortical neuronal recordings from the motor cortex have been pioneered by Delgado et al in 1952 and Evarts conducted further groundbreaking work capturing extracellular neural activity from single recording units in conscious primates engaged in diverse motor tasks. Today, almost 60 years later, neural recording has undergone a revolutionary evolution owing to innovative technologies such as high-density probes, high-density microelectrode array, and carbon nanotube yarn biosensors. These technologies have made it possible to record the activities of more neurons with a higher spatial resolution and coverage and have paved the way for more clinically viable and high-performance iBCIs. BCIs help subjects with disabilities to interact with external devices, such as neuroprosthetics, or restore lost sensory, motor, or cognitive functions by translating neural activity from the brain into control commands through neural decoding. In addition to therapeutic applications, iBCIs advance our understanding of the complex neural processes that underlie behavior, cognition, and perception.
皮层内神经元记录由 Delgado 等人在 1952 年开创,Evarts 在捕捉参与各种运动任务的清醒灵长类动物的单个记录单元的细胞外神经活动方面进行了进一步的开创性工作。今天,近 60 年后,神经记录经历了一场革命性的演变,这要归功于高密度探针、高密度微电极阵列和碳纳米管纱线生物传感器等创新技术。这些技术使得以更高的空间分辨率和覆盖范围记录更多神经元的活动成为可能,并为更具临床可行性和高性能的 iBCI 铺平了道路。BCI 通过神经解码将大脑中的神经活动转换为控制命令,帮助残疾人群与外部设备(如神经假体)交互或恢复丧失的感觉、运动或认知功能。除了治疗应用外,iBCI 还增进了我们对行为、认知和感知背后的复杂神经过程的理解。
Two types of BCIs can be distinguished: non-invasive and invasive. Invasive BCIs involve implanting electrodes into or on the cortex. iBCIs are a specific subtype of invasive BCIs, in which electrodes are inserted into the cortex, which is the outermost layer of the brain. They provide the finest spatial and temporal resolutions and excellent signal quality. Although iBCIs carry a higher risk owing to surgical implantation, their superior spatiotemporal resolution is crucial for high-precision neural decoding.
可以区分两种类型的 BCI:非侵入性和侵入性。侵入性 BCI 涉及将电极植入或放置在皮层上。iBCI 是侵入性 BCI 的一个特定亚型,其中电极插入大脑的最外层皮层。它们提供了最精细的空间和时间分辨率以及出色的信号质量。尽管 iBCI 由于外科手术植入而带来更高的风险,但其卓越的时空分辨率对于高精度神经解码至关重要。
CLN
One promising field for iBCI is neuromodulation. Traditionally, neuromodulation described the physiological processes by which neurons use neurotransmitters to regulate neural activity. More recently, neuromodulation has been adapted to refer to the process of altering neural activity via electrical stimulation to restore normal neurological functions or study intra-cortical interaction. Neuromodulation can be classified into open and closed-loop systems, as shown in figure 1. Open-loop neuromodulation involves delivering neural stimulation without real-time feedback from the targeted neural system with predefined and fixed stimulation parameters, such as strength or timing. In contrast, CLN with iBCI uses bi-directional communication between the brain and the computing devices, providing adaptive feedback to adapt and adjust the parameters of interventions, enabling personalized and responsive therapeutic neural modulation based on the subject’s neural activity. The adaptive and interactive nature of CLN enhances efficacy, i.e. maximizing the therapeutic impact and leading to more successful treatments, and reduces the side effects of neural stimulations (e.g. discomfort, headache, or worst case seizure). For the remainder of this paper, CLN refers exclusively to neuromodulation via iBCI.
iBCI 的一个有前途的领域是神经调节。传统上,神经调节描述了神经元使用神经递质调节神经活动的生理过程。最近,神经调节已被改编为指通过电刺激改变神经活动以恢复正常神经功能或研究皮层内相互作用的过程。神经调节可以分为开环和闭环系统,如图 1 所示。开环神经调节涉及在没有来自目标神经系统的实时反馈的情况下提供神经刺激,具有预定义和固定的刺激参数,例如强度或时间。相比之下,iBCI 的 CLN 使用大脑与计算设备之间的双向通信,提供自适应反馈以调整干预参数,实现基于受试者神经活动的个性化和响应性治疗性神经调节。CLN 的自适应和交互性质提高了疗效,即最大化治疗效果并导致更成功的治疗,并减少了神经刺激的副作用(例如不适、头痛或最坏情况癫痫发作)。在本文的其余部分中,CLN 专门指通过 iBCI 进行的神经调节。
Constraints of closed-loop neuromodulation
CLN typically requires a powerful external computer to decode complex neural activities. More sophisticated neural tasks (e.g. sensory and motor cortex interaction) require high channel counts of neural recording with fine spatial and temporal resolutions, generating vast amounts of recording data, which impose significant limitations on the real-time applicability of neural decoders, see figure 2. Transferring data from the intra-cortical neural sensors to an external system requires energy-intensive wireless transmission, and limited wireless transmission bandwidth can increase the system’s latency. Moreover, the transfer of neural data for processing to an external computer raises privacy concerns. Many neural decoders for iBCI and CLN have been implemented in application-specific integrated circuit (ASICs), achieving low power consumption and miniature form factor, which demonstrates the feasibility of in vivo neural decoding.
闭环神经调节通常需要强大的外部计算机来解码复杂的神经活动。更复杂的神经任务(例如感觉和运动皮层交互)需要高通道数的神经记录,具有精细的空间和时间分辨率,生成大量的记录数据,这对神经解码器的实时适用性施加了重大限制,见图 2。从皮层内神经传感器向外部系统传输数据需要耗能的无线传输,有限的无线传输带宽会增加系统的延迟。此外,将神经数据传输到外部计算机进行处理会引发隐私问题。许多用于 iBCI 和 CLN 的神经解码器已在专用集成电路 (ASIC) 中实现,实现了低功耗和微型化形式因素,展示了体内神经解码的可行性。
Advantages and disadvantages of external and local processing. (a) External processing requires transferring neural data or extracted features to an external computing device. Wireless data transfer suffers from long latency, high transmission energy, and privacy concerns. (b) Local neural processing has the potential to be significantly faster, with low transmission energy, at the cost of little flexibility.
外部和本地处理的优缺点。(a) 外部处理需要将神经数据或提取的特征传输到外部计算设备。无线数据传输存在长延迟、高传输能耗和隐私问题。(b) 本地神经处理有可能显著更快,传输能耗低,但灵活性较差。
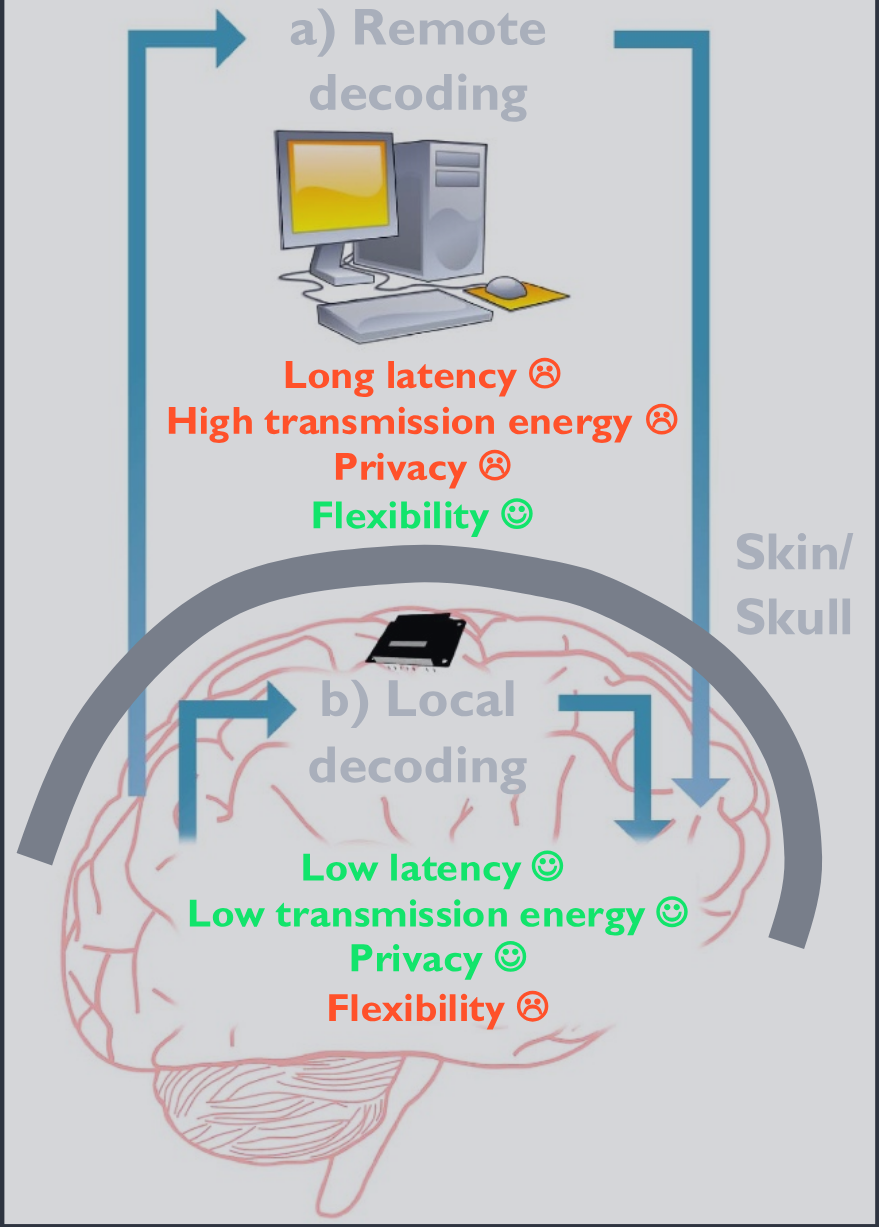
To address these concerns, data transmission can be avoided by eliminating the need for external computing and decoding neural signals locally on the implant. This eliminates the necessity for intensive data communication collectively except for programming the implant or diagnostics. Valencia and Alimohammad highlighted the need for local processing in a fully implantable iBCI for in vivo closed-loop neural decoding, eliminating data transmission during inference and significantly reducing energy consumption, latency, and privacy concerns.
为了解决这些问题,可以通过消除对外部计算的需求并在植入物上本地解码神经信号来避免数据传输。这消除了除了对植入物进行编程或诊断之外的密集数据通信的必要性。Valencia 和 Alimohammad 强调了在体内闭环神经解码的全植入式 iBCI 中进行本地处理的必要性,消除了推理过程中的数据传输,并显著降低了能耗、延迟和隐私问题。
Designing iBCIs for CLN is challenging because of the highly resource-constrained environment of implants. The implant volume should be minimized to reduce the invasiveness and risks of the surgery, and low power consumption is required to prevent tissue damage due to even a one degree temperature increase. However, iBCIs are required to process an exponentially growing amount of neural data, which adds to the complexity of the decoding task. Minimal heat diffusion is required to ensure safe local processing, without causing tissue damage. While Wolf initially cautiously recommended limiting the temperature of implant electronics to below 40 available at: heat flux and 2 ◦C, a much lower bound of 1 ◦C is vital to maintain long-term neural cell health. This means that a 10 mm2 of implant electronics cannot exceed a power dissipation of 400 μW, which is ∼10× lower than that of smartphone processors (e.g. the microprocessor in iPhone concerns 100’s mW of power with an ASIC area of approximately 100 mm2). Given the conservative nature of these recommendations, minimizing power consumption beyond the stated limits is paramount. However, traditional processors cannot satisfy this power requirement, and low-power implants performing neural decoding algorithms is a major challenge to the successful clinical adoption of real-time closed-loop iBCIs.
为 CLN 设计 iBCI 具有挑战性,因为植入物的资源极其受限的环境。为了减少手术的侵入性和风险,应尽量减少植入物的体积,并且需要低功耗以防止由于即使温度只升高一度而导致的组织损伤。然而,iBCI 需要处理指数增长的神经数据量,这增加了解码任务的复杂性。需要最小的热扩散以确保安全的本地处理,而不会造成组织损伤。 虽然 Wolf 最初谨慎地建议将植入电子设备的温度限制在 40 可用:热通量和 2 ◦C 以下,但为了维持长期神经细胞健康,1 ◦C 的更低界限至关重要。这意味着 $10\text{ mm}^{2}$ 的植入电子设备的功耗不能超过 $400 \mu\text{W}$,这大约是智能手机处理器(例如 iPhone 中的微处理器,功率为数百毫瓦,ASIC 面积约为 100 mm2)的 10 倍。鉴于这些建议的保守性质,超出规定限制的最小化功耗至关重要。然而,传统处理器无法满足此功率要求,执行神经解码算法的低功耗植入物是实时闭环 iBCI 成功临床采用的一大挑战。
Real-time processing is another crucial requirement for closed-loop iBCIs, in which continuous neural recording, decoding, and feedback occur in real time. This necessitates fast and efficient neural decoding algorithms to ensure timely and seamless interaction between the nervous system and the iBCI. Controlling a robotic prosthesis requires a latency of less than 150 ms between neural activity and arm movement for smooth and natural control, which is close to the biological delay for signal propagation between the brain and the arm. However, immediate feedback is crucial for the neural decoder to adjust the control system in real-time, allowing subjects to adapt and refine their actions in real-time. In this closed-loop iBCI, much lower latency of less than 10 ms is necessary for decoding inter-areal interactions (e.g. sensory and motor) in the brain.
实时处理是闭环 iBCI 的另一个关键要求,其中连续的神经记录、解码和反馈实时发生。这需要快速高效的神经解码算法,以确保神经系统与 iBCI 之间的及时无缝交互。控制机器人假肢需要在神经活动和手臂运动之间的延迟小于 150 毫秒,以实现平稳自然的控制,这接近大脑与手臂之间信号传播的生物学延迟。然而,立即反馈对于神经解码器实时调整控制系统至关重要,使受试者能够实时适应和完善其动作。在这种闭环 iBCI 中,对于解码大脑中的区域间交互(例如感觉和运动),需要更低的延迟,低于 10 毫秒。
Metrics
Traditionally, neural decoders have been the primary evaluated on decoding performance. However, in hardware-constrained iBCIs, other factors, such as latency and power consumption, are crucial to ensure the tractability of neural decoders for applications such as CLN. Evaluating decoders solely on task performance often fails to capture their true potential but also limitations. This chapter introduces the need for comprehensive metrics for algorithmic evaluation that encompass fidelity (i.e. accuracy), latency, power consumption, and memory size for neural decoders. Table 1 presents an overview of the proposed evaluation metrics.
传统上,神经解码器主要评估解码性能。然而,在硬件受限的 iBCI 中,延迟和功耗等其他因素对于确保神经解码器在 CLN 等应用中的可处理性至关重要。仅根据任务性能评估解码器通常无法捕捉其真正的潜力,也无法捕捉其局限性。本章介绍了全面指标的必要性,用于涵盖神经解码器的保真度(即准确性)、延迟、功耗和内存大小的算法评估。表 1 提出了所建议的评估指标的概述。
Metric Explaination Fidelity $R^{2}\\r$ Proportion of explainable data variance $\\$ Temporal alignment of label and prediction Latency Binning latency $\\$ Processing latency Timespan of input data needed per inference $\\$ Operational delay optimized by the algorithm designer Power consumption Total eff. operations $\\$ Memory access Number of effective operations needed per inference $\\$ Number of effective memory access needed per inference Size Memory footprint Number of bits required to store the decoder
| 指标 | 解释 | |
|---|---|---|
| 保真度 | $R^{2}\\r$ | 可解释数据方差的比例 $\\$ 标签和预测的时间对齐 |
| 延迟 | 分箱延迟 $\\$ 处理延迟 | 每次推理所需的输入数据时间跨度 $\\$ 由算法设计师优化的操作延迟 |
| 功耗 | 总有效操作 $\\$ 内存访问 | 每次推理所需的有效操作数 $\\$ 每次推理所需的有效内存访问数 |
| 大小 | 内存占用 | 存储解码器所需的位数 |
Model fidelity
The fidelity of a neural decoder in an iBCI is its ability to correctly classify or predict. In closed-loop iBCI, making accurate predictions is crucial for effective and reliable control of external devices or neural stimulations, which should closely reflect the subject’s intention or state.
iBCI 中神经解码器的保真度是其正确分类或预测的能力。在闭环 iBCI 中,做出准确的预测对于有效可靠地控制外部设备或神经刺激至关重要,这应与受试者的意图或状态密切相关。
Classification accuracy has traditionally been used to assess neural decoding performance by determining the percentage of correct classifications of stimuli, such as odors, faces, or speech. However, these metrics do not consider the temporal continuity of neural data, which is critical for many neural decoding applications. Neural decoding tasks require metrics that incorporate the correction of the temporal regression to evaluate decoding accuracy. In such cases, the coefficient of determination ($R^2$) and the coefficient of correlation (Pearson's $r$) are widely used to assess the performance of neural decoding algorithms.
传统上,分类准确性已被用来评估神经解码性能,通过确定对刺激(如气味、面孔或语言)的正确分类的百分比。然而,这些指标没有考虑神经数据的时间连续性,而这对于许多神经解码应用至关重要。神经解码任务需要结合时间回归校正的指标来评估解码精度。在这种情况下,决定系数 ($R^2$) 和相关系数(Pearson 的 $r$)被广泛用于评估神经解码算法的性能。
The $R^2$ measures the proportion of variance in the dependent variable explained by the model’s prediction, while Pearson’s $r$ evaluates the temporal alignment of the predictions and labels via a linear relationship. Both metrics should be reported to assess the temporal regression performance of the neural decoder comprehensively.
$R^2$ 衡量模型预测解释的因变量方差的比例,而 Pearson 的 $r$ 通过线性关系评估预测和标签的时间对齐。应报告这两个指标,以全面评估神经解码器的时间回归性能。
Latency
The latency of the neural decoder, defined as the time delay between the first input stimulus and the output response, comprises two architecture-specific subcomponents: the binning latency and the processing latency (see figure 3(c)). This allows for a platform- and architecture-agnostic evaluation of neural decoders.
神经解码器的延迟定义为从第一个输入刺激到输出响应之间的时间延迟,包括两个特定于架构的子组件:分箱延迟 和 处理延迟(见图 3(c))。这允许对神经解码器进行平台和架构无关的评估。
Experimental pipeline for evaluating closed-loop capability of neural decoders. (a) A primate consecutively reaches for black boxes on a grid. Neural activity is recorded using one or two UTAH arrays placed at the primary motor and sensorimotor cortices, while finger position is tracked through an electromagnetic position sensor. Finger velocity is computed and used as a decoding target. (b) Neural activity is processed as a spike train, binned, and processed by the neural decoding system to predict finger velocity. (c) The visualization illustrates the latency of the entire decoding system, composed of binning latency and processing latency.
评估神经解码器闭环能力的实验流程。(a) 灵长类动物连续地伸手去抓网格上的黑色盒子。使用放置在初级运动皮层和感觉运动皮层的一个或两个 UTAH 阵列记录神经活动,同时通过电磁位置传感器跟踪手指位置。计算手指速度并用作解码目标。(b) 神经活动被处理为脉冲序列,进行分箱,并由神经解码系统处理以预测手指速度。(c) 可视化说明了整个解码系统的延迟,由分箱延迟和处理延迟组成。
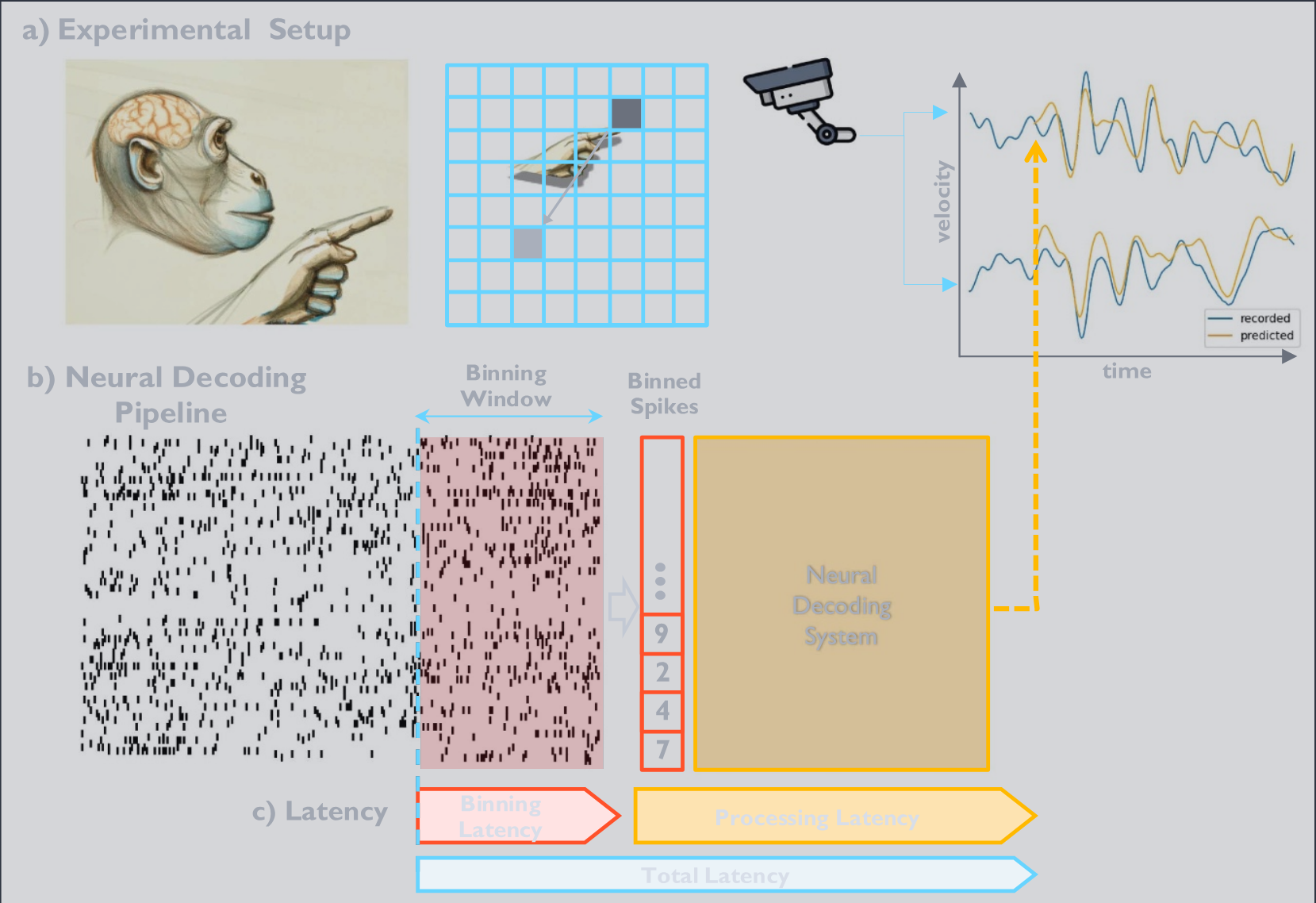
The binning latency corresponds to the time span of the input data required for each prediction. This equates to the binning time window or the history of binning windows in the case of multiple windows. Minimizing binning window size is crucial for limiting total latency.
分箱延迟 对应于每次预测所需的输入数据的时间跨度。这相当于分箱时间窗口,或者在多个窗口的情况下为分箱窗口的历史。最小化分箱窗口大小对于限制总延迟至关重要。
The processing latency is caused by the processing time for a neural decoder to produce a prediction. This combines the operational delay of preprocessing, network inference, and postprocessing. The processing time is bound by a function of the system’s required effective operations per inference, which can be assessed by computing the effective multiply-and-accumulate (MAC) operations of neural decoder algorithms. This definition ignores a potential speed-up of parallel processing, which would require binding the algorithm to hardware. Latency can be reported in wall time, such as absolute SI units, or relative system time, as the total number of clock cycles per inference. This paper reports latency in milliseconds, providing a more intuitive and user-centric perspective and allowing the reader to assess the system’s ability to deliver timely and accurate responses. Converting the processing latency into seconds requires platform-specific assumptions regarding the required clock cycles per operation, the clock frequency, and a system’s capability for parallel processing. For the remainder of this paper, a clock frequency of 1 MHz and 3 MAC operations per clock cycle were assumed, to provide a more intuitive comparison of the latency of the evaluated decoders. For simplicity, one addition corresponding to the sparse synaptic operation of neurons in the SNN is assumed to be equivalent to one MAC in terms of required clock cycles.
处理延迟 是神经解码器生成预测所需的处理时间引起的。这结合了预处理、网络推理和后处理的操作延迟。处理时间受系统每次推理所需的有效操作数函数的约束,可以通过计算神经解码器算法的有效乘加 (MAC) 操作来评估。 这一定义忽略了并行处理的潜在加速,这将需要将算法绑定到硬件。延迟可以以墙时(例如绝对 SI 单位)或相对系统时间(每次推理的总时钟周期数)报告。本文以毫秒为单位报告延迟,提供了更直观和以用户为中心的视角,并允许读者评估系统提供及时准确响应的能力。将处理延迟转换为秒需要关于每次操作所需时钟周期、时钟频率和系统并行处理能力的平台特定假设。 在本文的其余部分,假设时钟频率为 1 MHz,每个时钟周期 3 次 MAC 操作,以提供对评估解码器延迟的更直观比较。为了简化起见,假设与 SNN 中神经元稀疏突触操作对应的一次加法在所需时钟周期方面等同于一次 MAC。
Power consumption
Power consumption is vital to evaluating neural decoders, particularly in resource-constrained iBCIs suitable for CLN. Local neural processing, which is implemented directly on an embedded device, is usually preferable to external processing due to latency, communication bandwidth, and privacy issues. However, local neural processing requires low energy consumption to minimize tissue heating.
功耗对于评估神经解码器至关重要,尤其是在适用于 CLN 的资源受限 iBCI 中。直接在嵌入式设备上实现的本地神经处理通常优于外部处理,因为存在延迟、通信带宽和隐私问题。然而,本地神经处理需要低能耗以最小化组织加热。
To compare the energy efficiency of different neural decoders in a hardware- and architecture-independent manner, one can benchmark with two hardware-agnostic metrics: total effective operations and memory accesses. This considers only algorithmic optimizations, such as reducing effective operational costs. Although algorithm-hardware co-optimizations can further improve latency, performance, and energy efficacy, they require binding the neural decoder to specific hardware and, thus, are not considered in this study.
为了以硬件和架构无关的方式比较不同神经解码器的能效,可以使用两个硬件无关的指标进行基准测试:总有效操作和内存访问。这仅考虑算法优化,例如减少有效操作成本。尽管算法-硬件协同优化可以进一步提高延迟、性能和能量效率,但它们需要将神经解码器绑定到特定硬件,因此在本研究中不予考虑。
The total effective operations are reported as the number of non-zero operations required per inference. This combines two relevant operations that dominate neural network operations: multiplication and addition. To estimate the energy consumption of a neural decoder, however, total operations should be reported instead of MAC and ACC since these operations are assumed to be optimized by vector accelerators, which is the bottleneck for latency but does not reflect well on the energy cost of a neural decoder. To reduce energy consumption, neural decoders can exploit the sparsity of the spiking data by distinguishing between effective and ineffective operations. This accounts for only non-zeros contributing to the products and, consequently, the accumulation, which can be leveraged by specialized hardware. Reporting the effective computational cost as the number of non-zero operations allows for hardware-agnostic comparison of different networks, considering computational primitives in neuromorphic neural networks. In the remainder of this paper, MAC denotes effective MAC operations.
总有效操作报告为每次推理所需的非零操作数。这结合了主导神经网络操作的两个相关操作:乘法和加法。然而,为了估计神经解码器的能耗,应报告总操作数而不是 MAC 和 ACC,因为这些操作假定由向量加速器优化,这是延迟的瓶颈,但不能很好地反映神经解码器的能量成本。为了降低能耗,神经解码器可以通过区分有效和无效操作来利用脉冲数据的稀疏性。这仅考虑对乘积和因此累积有贡献的非零项,这可以被专用硬件利用。将有效计算成本报告为非零操作数允许对不同网络进行硬件无关的比较,考虑神经形态神经网络中的计算原语。在本文的其余部分,MAC 表示有效 MAC 操作。
Reporting memory access is crucial for comprehensively estimating the energy consumption of neural decoders. Because a read-and-write operation to the memory requires one to two orders of magnitude more energy than operations of arithmetic linear units, it is insufficient to report only effective operations without including the memory access. Furthermore, Liao et al report ∼10× more reads than effective operations during inference, highlighting that most of the energy consumption of an architecture comes from the memory read-and-write operations. Following their approach, the number of memory accesses in a network is conservatively estimated by assuming that a MAC operation consists of three loads and one store. By contrast, an ACC consists of two loads and one store, which both, similarly to before, need to be combined with the sparseness of activity of the network.
报告内存访问对于全面估计神经解码器的能耗至关重要。因为对内存的读写操作所需的能量比算术线性单元的操作高出一个到两个数量级,仅报告有效操作而不包括内存访问是不够的。此外,Liao 等人在推理过程中报告了大约 10 倍于有效操作的读取次数,强调了架构的大部分能耗来自内存读写操作。遵循他们的方法,通过假设 MAC 操作由三次加载和一次存储组成,保守地估计网络中的内存访问次数。相比之下,ACC 由两次加载和一次存储组成,与之前类似,都需要与网络活动的稀疏性相结合。
Memory footprint
Due to space volume constraints of iBCIs, the memory size, which in comparison to other function blocks consumes far more ASIC area, should be reported. If the memory requirements of the neural decoder are too large, external memory is required, which can consume more than 100× more energy than on-chip memory. Estimating the memory footprint of a neural decoder involves calculating the sum of the network’s parameters and variables, as well as the memory requirements of input data from binning windows. The memory size should be reported in bits to provide credit to architectures that limit the precision of weights.
由于 iBCI 的空间体积限制,内存大小应予以报告,因为与其他功能块相比,它消耗了更多的 ASIC 面积。如果神经解码器的内存需求过大,则需要外部内存,其能耗可能超过片上内存的 100 倍。估计神经解码器的内存占用涉及计算网络参数和变量的总和,以及来自分箱窗口的输入数据的内存需求。内存大小应以位为单位报告,以表彰限制权重精度的架构。
Methods
The methodology is structured into five subsections, addressing how this study evaluates and benchmarks various neural decoders within the context of iBCI for CLN. The first subsection provides an overview of the neural data utilized in this benchmark, which comprises neural activity recorded from non-human primates, representing a relevant scenario for closed-loop iBCI applications. Decoders are categorized into three main groups: traditional neural decoders, artificial neural networks (ANN)-based neural decoders, and neuromorphic spiking neural network (SNN)-based decoders. The selection of traditional and ANN decoders was based on existing literature, while the long short-term memory (LSTM) and SNN-based decoders were optimized for this study. The presented decoders are non-exhaustive (the interested reader is referred to recently proposed models), yet the decoders aim to represent commonly used neural decoding methods. The final subsection outlines the experimental setup and details the conditions and parameters under which the benchmark was conducted. These methodological components provide a detailed pipeline for evaluating neural decoding methods for closed-loop iBCI applications.
该方法分为五个子部分,解决了本研究如何在 CLN 的 iBCI 背景下评估和基准测试各种神经解码器。第一个子部分概述了本基准测试中使用的神经数据,这些数据包括从非人类灵长类动物记录的神经活动,代表了闭环 iBCI 应用的相关场景。解码器分为三大类:传统神经解码器、基于人工神经网络 (ANN) 的神经解码器和基于神经形态脉冲神经网络 (SNN) 的解码器。传统和 ANN 解码器的选择基于现有文献,而长短期记忆 (LSTM) 和 SNN 基解码器则针对本研究进行了优化。所呈现的解码器并非详尽无遗(有兴趣的读者可参考最近提出的模型),但这些解码器旨在代表常用的神经解码方法。最后一个子部分概述了实验设置,并详细说明了进行基准测试的条件和参数。这些方法论组件为评估闭环 iBCI 应用的神经解码方法提供了详细的流程。
Neural recording dataset
The ANN and SNN neural decoders were trained and benchmarked on the ‘primate reaching task’ of the neuromorphic benchmark NeuroBench, as visualized in figures 3(a) and (b). This benchmark employs the same data as Makin et al, which previously were used to evaluate their traditional decoders. The $R^{2}$ value published by Makin et al is reported here, and the metrics for power consumption and latency are calculated conservatively based on the most time-consuming and energy-intensive matrix operations, as defined in Chapters 4.2 and Chapter 4.3.
ANN 和 SNN 神经解码器在神经形态基准 NeuroBench 的“灵长类动物伸手任务”上进行了训练和基准测试,如图 3(a) 和 (b) 所示。该基准测试使用与 Makin 等人相同的数据,之前用于评估他们的传统解码器。这里报告了 Makin 等人发布的 $R^{2}$ 值,并根据第 4.2 章和第 4.3 章中定义的最耗时和最耗能的矩阵操作,保守地计算了功耗和延迟的指标。
The dataset is a subset of 6 out of 33 recording sessions of 2 Rhesus primates during subsequent reaching tasks as shown in figure 3(a), which was released by Dyer et al. These sessions encompassed two non-human primates (NHPs) and the entire recording period. Three NHP ‘I’ sessions were recorded using a 96-channel Utah array from Blackrock Neurotech implanted in the primary motor cortex. The three NHP ‘L’ sessions had an additional Utah array in the sensorimotor cortex, enabling the simultaneous recording of 192 channels. Each recording session comprises 354–819 individual reaches, and those longer than 8 s were discarded as they indicate the primate’s inattention.
该数据集是 Dyer 等人发布的 2 只恒河猴在随后的伸手任务期间的 33 个记录会话中的 6 个子集,如图 3(a) 所示。这些会话涵盖了两只非人类灵长类动物 (NHPs) 和整个记录期。三次 NHP“I”会话使用 Blackrock Neurotech 植入初级运动皮层的 96 通道 Utah 阵列进行记录。三次 NHP“L”会话在感觉运动皮层中增加了一个 Utah 阵列,实现了 192 通道的同时记录。每个记录会话包括 354-819 次单独的伸手动作,超过 8 秒的动作被丢弃,因为它们表明灵长类动物不专心。
Spikes were detected from the raw neural data using a threshold of 3.5–4 times the root-mean-square (RMS) noise. The finger position was recorded using an electromagnetic position sensor at 250 Hz, and the velocity was computed as the discrete gradient of the position. Predicting the translation invariant finger velocity better aligns with the natural dynamics of limb movements and corresponds to how neural activity encodes kinematics. Makin et al, and Dyer et al report the detailed experimental setup and the data acquisition.
从原始神经数据中使用 3.5-4 倍均方根 (RMS) 噪声的阈值检测脉冲。手指位置使用电磁位置传感器以 250 Hz 的频率记录,并计算为位置的离散梯度。预测平移不变的手指速度更好地符合肢体运动的自然动态,并且与神经活动如何编码运动学相对应。Makin 等人和 Dyer 等人报告了详细的实验设置和数据采集。
Traditional neural decoders
Classic neural decoding methods have been extensively used in brain-computer interfacing. Of the six decoders Makin et al presented, the three best-performing models were selected to represent traditional neural decoders. Those decoders are the ‘unscented’ Kalman Filter (UKF), the static, and the dynamic ‘recurrent exponential-family harmonium’ (rEFH), and they are evaluated due to their established performance and versatility in handling various neural data modalities. Makin et al also considered linear regression, conventional KF, and Wiener filter. However, since these decoders had worse $R^{2}$ performance and scaled poorly with decreasing binning windows, they were not considered suitable for this neural decoding benchmark for closed-loop iBCIs suitable for CLN.
经典神经解码方法已被广泛用于脑机接口。在 Makin 等人提出的六种解码器中,选择了表现最好的三种模型来代表传统神经解码器。这些解码器是“无迹”卡尔曼滤波器 (UKF)、静态和动态“递归指数族谐振器” (rEFH),由于其在处理各种神经数据模态方面的既定性能和多功能性而进行评估。Makin 等人还考虑了线性回归、传统 KF 和 Wiener 滤波器。然而,由于这些解码器的 $R^{2}$ 性能较差,并且随着分箱窗口的减小而扩展性差,因此它们不适合用于适用于 CLN 的闭环 iBCI 的神经解码基准测试。
The UKF approximates the state distribution by applying a full nonlinearity to a minimal set of carefully selected representative points. It was designed as an extension of the KF to address the problem of its exploding residuals on the true posterior mean and covariance. The UKF solves this by replacing the normal sampled state distribution with a deterministic sampling of this distribution. The UKF, as described by Makin et al and Wan et al, has a state space of deterministically sampled 40 variables, which requires $O (n^3/6)$ operations due to Cholesky decomposition. As a conservative estimate of the processing latency and the operational cost, only matrix multiplications required during inference and the computationally intensive matrix inversion were considered. This large-scale matrix inversion was assumed to require at least 200 ms.
UKF 通过对精心选择的代表点集应用完整的非线性来近似状态分布。它被设计为 KF 的扩展,以解决其在真实后验均值和协方差上的残差爆炸问题。UKF 通过用该分布的确定性采样替换正常采样的状态分布来解决此问题。正如 Makin 等人和 Wan 等人所描述的那样,UKF 具有确定性采样的 40 个变量的状态空间,由于 Cholesky 分解需要 $O (n^3/6)$ 操作。作为处理延迟和操作成本的保守估计,仅考虑了推理过程中所需的矩阵乘法和计算密集型矩阵求逆。假设这种大规模矩阵求逆至少需要 200 毫秒。
The rEFH, instead of assuming Gaussian state variables, models the state variables as a variant of a restricted Boltzmann Machine (RBM) and explicitly samples the spike count from a Poisson distribution. The static variant converts the latent space of the RBM into kinematics via static mapping, that is, a matrix multiplication, whereas the dynamic version uses a KF. For the static and the dynamic rEFH models, only the forward pass of the RBM uses higher-dimensional matrix multiplications, and thus is considered. There are four times as many hidden neurons in the RBM than there are input channels and 1800 output neurons mapped to the kinematic output via either a matrix multiplication or a KF. All traditional decoders were evaluated using binning windows of 16 ms, 32 ms, 64 ms, and 128 ms.
rEFH 不假设高斯状态变量,而是将状态变量建模为受限玻尔兹曼机 (RBM) 的变体,并明确地从泊松分布中采样脉冲计数。静态变体通过静态映射(即矩阵乘法)将 RBM 的潜在空间转换为运动学,而动态版本则使用 KF。对于静态和动态 rEFH 模型,仅 RBM 的前向传递使用更高维的矩阵乘法,因此予以考虑。RBM 中的隐藏神经元数量是输入通道数量的四倍,1800 个输出神经元通过矩阵乘法或 KF 映射到运动学输出。所有传统解码器均使用 16 毫秒、32 毫秒、64 毫秒和 128 毫秒的分箱窗口进行评估。
ANNs
This study used two ANN-based decoders as baselines owing to their established history of high-accuracy predictions. Previous studies have demonstrated that ANN-based decoders perform on par or better than traditional decoders. One fully connected ANN, published as a baseline for the NeuroBench benchmark, and one LSTM network were evaluated.
本研究使用了两个基于 ANN 的解码器作为基线,因其在高精度预测方面的既定历史。先前的研究表明,基于 ANN 的解码器的性能与传统解码器相当或更好。评估了一个作为 NeuroBench 基准基线发布的全连接 ANN 和一个 LSTM 网络。
The ANN is a conventional 3-layer feedforward network with 32 and 48 hidden and two output neurons, respectively. This implementation uses a history of multiple non-overlapping binning windows that are flattened and processed as input data. The default implementation, including the history of 7 binning windows, is shown in figure 4(a). To explore the latency versus fidelity trade-off, a history of 4, 7, and 14 binning windows of 28 ms was considered, and the number of neurons in the hidden layers halved and doubled.
ANN 是一个传统的三层前馈网络,分别具有 32 个和 48 个隐藏神经元以及两个输出神经元。该实现使用多个不重叠分箱窗口的历史记录,这些窗口被展平并作为输入数据进行处理。默认实现包括 7 个分箱窗口的历史,如图 4(a) 所示。为了探索延迟与保真度的权衡,考虑了 28 毫秒的 4、7 和 14 个分箱窗口的历史记录,并将隐藏层中的神经元数量减半和加倍。
Architecture of three neural network-based decoders. The data extraction and binning are visualized in red, and the network architecture in blue. Each layer’s dimensions and type are stated above and below, respectively. (a) The ANN uses seven binning windows spanning 28 ms as input. These extracted windows are flattened and processed by two hidden layers with 32 and 48 Neurons, respectively. (b) The LSTM extracts spikes with a temporal resolution of 4 milliseconds, effectively representing the neural data as a spike train. Then, the data undergoes dimensionality reduction via a fully connected (FC) layer with 16 neurons, after which a long short-term memory (LSTM) cell is employed. (c) Similarly, the SNN decoder extracts the spike train and processes it through a network featuring 50 hidden Leaky Integrate-and-Fire (LIF) neurons. The final output of this network comprises the membrane potential of two LIF neurons.
三种基于神经网络的解码器的架构。数据提取和分箱以红色可视化,网络架构以蓝色可视化。每一层的维度和类型分别在上方和下方说明。 (a) ANN 使用跨越 28 毫秒的七个分箱窗口作为输入。这些提取的窗口被展平,并分别由两个具有 32 和 48 个神经元的隐藏层处理。 (b) LSTM 以 4 毫秒的时间分辨率提取脉冲,有效地将神经数据表示为脉冲序列。然后,数据通过具有 16 个神经元的全连接 (FC) 层进行降维,之后使用长短期记忆 (LSTM) 单元。 (c) 类似地,SNN 解码器提取脉冲序列,并通过一个具有 50 个隐藏泄漏积分与发放 (LIF) 神经元的网络进行处理。该网络的最终输出包括两个 LIF 神经元的膜电位。
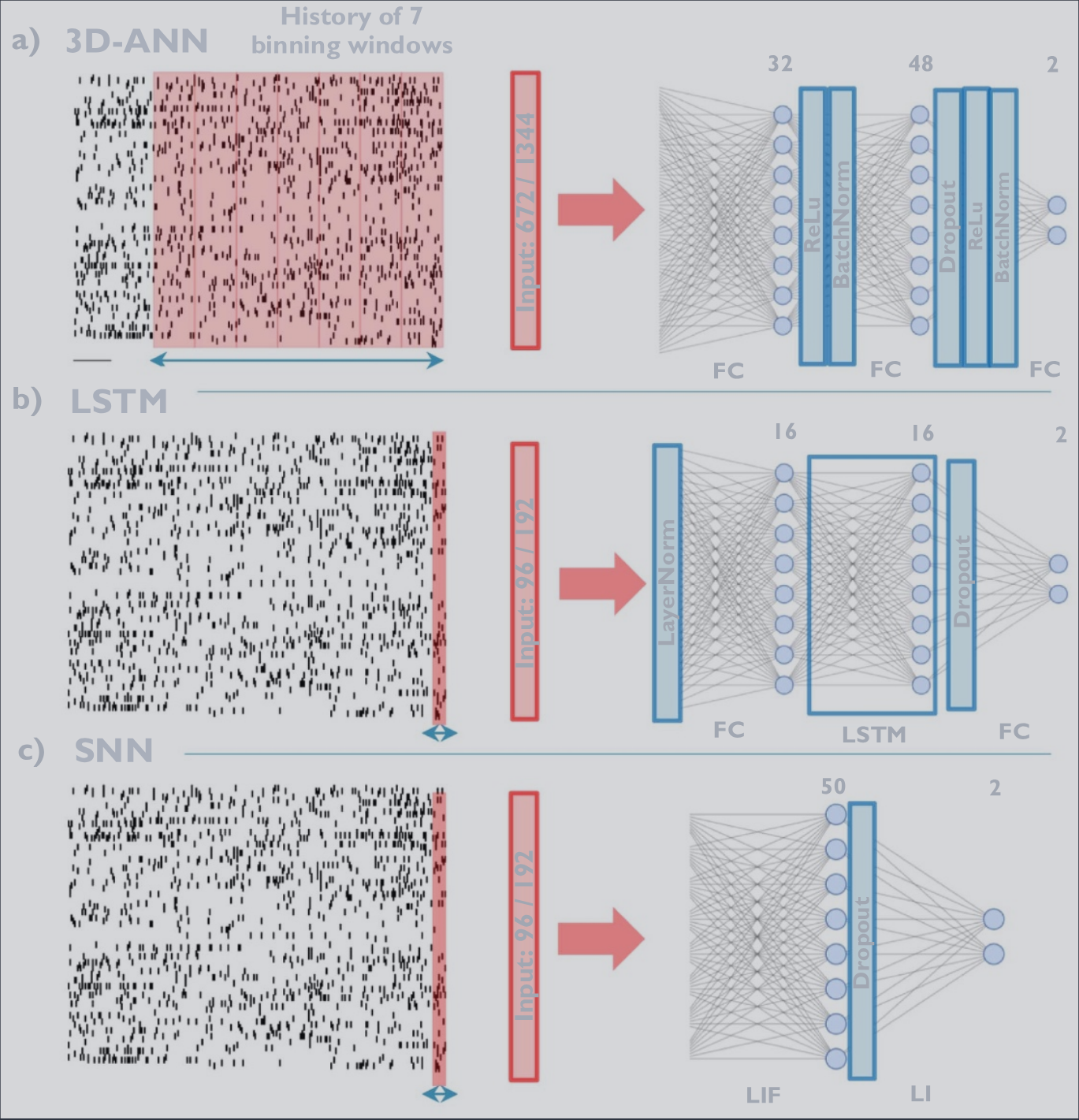
The LSTM, as shown in figure 4(b), uses a fully connected layer to reduce the input dimensionality to 16, followed by a single LSTM cell with 16 hidden neurons. A feedforward layer returns the predicted kinematics. Similar to the ANN, binning windows of 4 ms, 8 ms, and 16 ms and wider networks, with 64 and 128 hidden neurons, were examined. The networks use batch normalization (BatchNorm) and layer normalization (LayerNorm), respectively, and use Dropout.
LSTM 如图 4(b) 所示,使用全连接层将输入维度降低到 16,随后是一个具有 16 个隐藏神经元的单个 LSTM 单元。一个前馈层返回预测的运动学。与 ANN 类似,检查了 4 毫秒、8 毫秒和 16 毫秒的分箱窗口以及具有 64 和 128 个隐藏神经元的更宽网络。网络分别使用批量归一化 (BatchNorm) 和层归一化 (LayerNorm),并使用 Dropout。
SNN
SNNs are a variant of neural networks that attempt to mimic the properties, processes, and functions of biological neurons. This makes them inherently recurrent and allows them to exploit sparsity to achieve lower latency and power consumption. SNNs, at their core consist of stateful spiking neurons, a more bio-plausible variant of the Perceptron, with the leaky integrate-and-fire (LIF) being the most widely used neuron model. As the Perceptron, the LIF weighs and accumulates the input, but instead of returning this weighted accumulation, it is added to the neuron’s membrane potential. If the membrane potential exceeds a threshold, the neuron produces a binary output, that is, a spike, and the membrane potential is reset; otherwise, it decays per time step, as conceptually illustrated in figure 5. This enables the neuron to combine information over multiple time steps, making it inherently recurrent. In addition to their binary output, LIF neurons exploit binary input data, enabling sparsity in networks built around these neurons. The binary input separates the operations into effective and ineffective because multiplications by zero do not contribute to the accumulation. Therefore, the multiplication of weights times input can be forgone by adding only non-zero weights.
SNN 是神经网络的一种变体,试图模仿生物神经元的属性、过程和功能。这使它们本质上是递归的,并允许它们利用稀疏性来实现更低的延迟和功耗。SNN 的核心由有状态的脉冲神经元组成,这是一种更符合生物学的感知器变体,其中泄漏积分与发放 (LIF) 是最广泛使用的神经元模型。与感知器一样,LIF 对输入进行加权和累积,但不是返回这种加权累积,而是将其添加到神经元的膜电位中。如果膜电位超过阈值,神经元会产生二进制输出,即脉冲,并且膜电位会被重置;否则,它会随着时间步长而衰减,如图 5 所示的概念性说明。这使得神经元能够在多个时间步长上结合信息,使其本质上是递归的。除了它们的二进制输出外,LIF 神经元还利用二进制输入数据,使围绕这些神经元构建的网络具有稀疏性。二进制输入将操作分为有效和无效,因为乘以零不会对累积产生贡献。因此,可以通过仅添加非零权重来省略权重乘以输入的乘法。
A scheme of the LIF neuron. In this neuron model, incoming neural signals are integrated into the membrane potential, and if the accumulated value surpasses a specified threshold, the neuron generates a binary output signal. The ‘leaky’ property allows for the gradual decay of the accumulated charge, further contributing to the model’s simplicity. The intrinsic recurrent nature of the LIF neuron originates in the updated membrane potential.
LIF 神经元的示意图。在这种神经元模型中,传入的神经信号被整合到膜电位中,如果累积值超过指定的阈值,神经元会产生二进制输出信号。“泄漏”属性允许累积电荷逐渐衰减,进一步有助于模型的简化。LIF 神经元的内在递归性质源于更新的膜电位。

The implemented neuromorphic SNN decoder is a simplified version of the model proposed by Liao et al with fewer learnable parameters. In a preliminary exploration, reducing the complexity of the network only marginally impacted the accuracy while significantly improving the operational cost. Each hidden layer is decreased to 50 LIF-neurons without a bias term and a fixed decay ($\tau = 0.96$). The BatchNorm layer is removed because combining BatchNorm and Dropout leads to models with different feature variances inside the network during training and testing. The threshold of the LIF neurons is set to one. To further push for lower latency and power consumption and explore the various tradeoffs against accuracy, the number of hidden layers is decreased from three to two and one (SNN3, SNN2, and SNN1, respectively). SNN1 is a baseline model for the ‘primate reaching task’ of NeuroBench and is depicted in figure 4(c).
所实现的神经形态 SNN 解码器是 Liao 等人提出的模型的简化版本,具有更少的可学习参数。在初步探索中,减少网络的复杂性仅对准确性产生了边际影响,同时显著提高了操作成本。每个隐藏层减少到 50 个没有偏置项且具有固定衰减 ($\tau = 0.96$) 的 LIF 神经元。删除了 BatchNorm 层,因为将 BatchNorm 和 Dropout 结合会导致训练和测试期间网络内部具有不同特征方差的模型。LIF 神经元的阈值设置为 1。为了进一步推动更低的延迟和功耗,并探索与准确性之间的各种权衡,将隐藏层的数量从三个减少到两个和一个(分别为 SNN3、SNN2 和 SNN1)。SNN1 是 NeuroBench “灵长类动物伸手任务” 的基线模型,如图 4(c) 所示。
Experimental setup
The spike train was binned according to the window requirements of the respective network, and a sliding window with a stride of 4 ms extracted the spiking data. The RNNs and the SNNs used a sliding window of 50 bins to extract temporal information from the data and the non-recurrent ANNs extracted the bins individually. The neural decoders were trained to predict the finger velocity as visualized in figure 3.
脉冲序列根据各自网络的窗口要求进行分箱,并使用步幅为 4 毫秒的滑动窗口提取脉冲数据。RNN 和 SNN 使用 50 个分箱的滑动窗口从数据中提取时间信息,而非递归 ANN 则单独提取分箱。神经解码器经过训练以预测图 3 中所示的手指速度。
RNNs and SNNs notoriously suffer from difficulties when learning long-term dependencies from data. To improve the gradient flow, the SNN was trained to predict the time window of the primate’s finger kinematics and, for consistency, was tested to predict individual finger velocities as the ANNs. The Loss for this setup was a linearly weighted mean squared error (MSE) from zero to one to account for warm-up steps. The ANN and LSTM were trained using the conventional MSE Loss.
RNN 和 SNN 在从数据中学习长期依赖关系时臭名昭著地存在困难。为了改善梯度流,SNN 被训练以预测灵长类动物手指运动学的时间窗口,并且为了保持一致性,像 ANN 一样测试以预测单个手指速度。该设置的损失是从零到一的线性加权均方误差 (MSE),以考虑预热步骤。ANN 和 LSTM 使用传统的 MSE 损失进行训练。
Each session was divided into the first 75% of the reaches shuffled and, in contrast to the Neurobench-proposed evaluation pipeline, was used for model selection using 10-fold group cross-validation with early stopping and the last 25% for testing. This allows for finding the optimal hyperparameters and the number of training epochs while reporting more robust performance.
每个会话被划分为前 75% 的伸手动作进行洗牌,并与 Neurobench 提出的评估流程形成对比,用于使用 10 折组交叉验证和提前停止进行模型选择,最后 25% 用于测试。这允许找到最佳的超参数和训练周期数,同时报告更稳健的性能。
Results
We considered six decoders trained on reconstructing a primate’s finger velocity given binned neural activity with metrics that allow assessing a decoder’s latency and power consumption. The results in table 2 offer a complete overview of the performance of all decoders. The performance of the decoders is in line with previous literature given the reduced dataset, different training paradigms and different metrics.
我们考虑了六种解码器,这些解码器经过训练,可以根据分箱的神经活动重建灵长类动物的手指速度,并具有允许评估解码器延迟和功耗的指标。表 2 中的结果提供了所有解码器性能的完整概述。鉴于数据集的减少、不同的训练范式和不同的指标,解码器的性能与先前的文献一致。
Latency vs. fidelity
A higher $R^2$ performance can typically be achieved using deeper and more complex architectures or by better estimating the neural firing rate with a longer binning window. Both approaches negatively impact the latency and, thus, the capability of the neural decoder to facilitate real-time closed-loop feedback. The performance tradeoff of the six decoders is visualized in figure 6.
通常可以使用更深和更复杂的架构或通过更长的分箱窗口更好地估计神经发放率来实现更高的 $R^2$ 性能。这两种方法都会对延迟产生负面影响,从而影响神经解码器促进实时闭环反馈的能力。六种解码器的性能权衡如图 6 所示。
The accuracy versus latency trade-off of the six evaluated decoders. The R2 fidelity is plotted on the horizontal axis, and the vertical axis is the millisecond latency. In the plot, traditional decoders are represented as squares, artificial neural network-based decoders as triangles, and spiking neural networks (SNNs) as circles. The decoders with the best trade-off are in the bottom right corner. Recurrent decoders such as LSTM and SNN achieve substantially lower latency while maintaining competitive accuracy.
六种评估解码器的准确性与延迟权衡。水平轴上绘制了 $R^2$ 保真度,垂直轴为毫秒延迟。在图中,传统解码器表示为方块,基于人工神经网络的解码器表示为三角形,脉冲神经网络 (SNN) 表示为圆圈。具有最佳权衡的解码器位于右下角。诸如 LSTM 和 SNN 之类的递归解码器在保持竞争力的准确性的同时实现了显著较低的延迟。
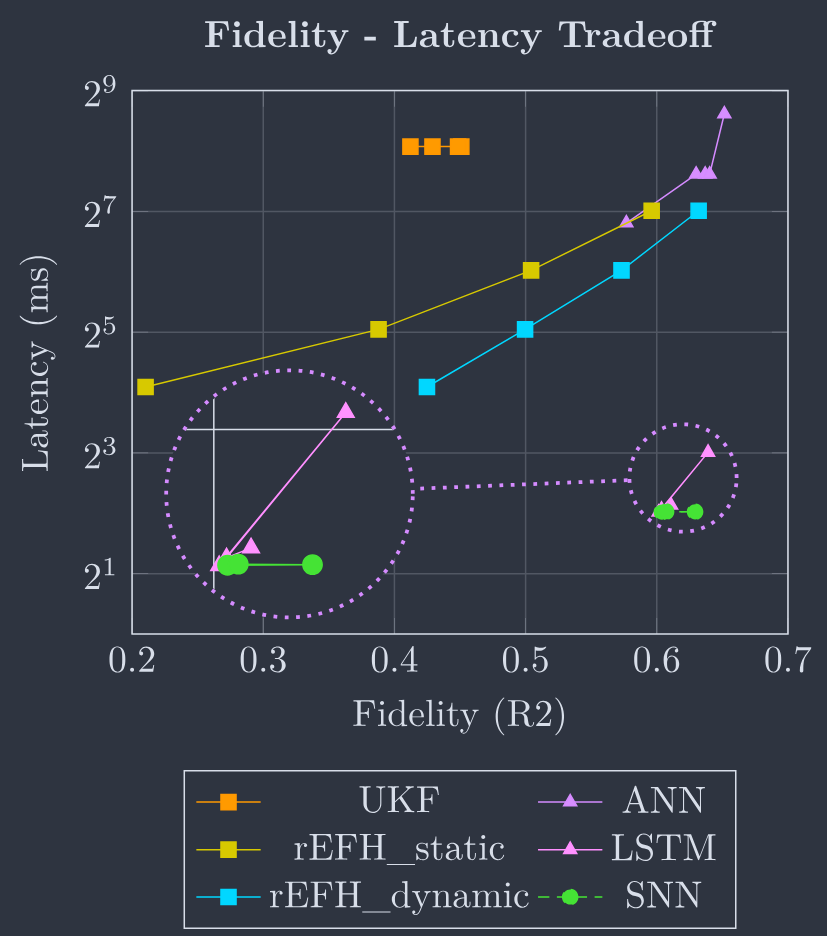
The UKF requires computationally intense matrix operations and a matrix inverse, making it significantly slower than the other decoders and achieving lower fidelity. Contrary to the rEFH filters, the $R^2$ score improved with decreasing binning windows. The best-performing rEFH filter had an $R^2$ of 63.19% (std = 0.17) with a latency of 129 ms, significantly outperforming the UKF with an $R^2$ of 45.10% (std = 0.12) and a latency of 270 ms both in terms of fidelity and latency.
UKF 需要计算密集型的矩阵操作和矩阵求逆,使其比其他解码器显著更慢且实现较低的保真度。与 rEFH 滤波器相反,随着分箱窗口的减小,$R^2$ 分数有所提高。表现最好的 rEFH 滤波器的 $R^2$ 为 63.19%(标准差 = 0.17),延迟为 129 毫秒,在保真度和延迟方面均显著优于 UKF,其 $R^2$ 为 45.10%(标准差 = 0.12),延迟为 270 毫秒。
The rEFH filters can achieve comparable $R^2$ scores to NN-based decoders. However, they require long binning windows to approximate the state distribution and experience a stark drop in the $R^2$ scores with smaller binning windows. Nevertheless, the trendlines of the rEFH and ANN models indicate that the rEFH can achieve a better latency versus fidelity tradeoff than the ANN. This stems from the ANN requiring a considerable history of binning windows to extract temporal information, which result in high latency. For the ANN, reducing the number of binning windows led to a significant decrease in fidelity. The shallow LSTM attains a much lower latency versus fidelity tradeoff than the traditional decoders and ANNs, indicated by the trendlines, achieving peak $R^2$ scores above 60% while having a latency between 4.05 ms and 16.05 ms. Notably, the fidelity drops significantly when using a longer binning window of 16 ms, indicating that the LSTM relies on the temporal dimension of the neural data to extract information about neural dynamics. The SNN achieved the best tradeoff with competitive $R^2$ scores and lower latency for all three models examined. The latency scales only marginally with an increasing number of layers.
rEFH 滤波器可以实现与基于 NN 的解码器相当的 $R^2$ 分数。然而,它们需要较长的分箱窗口来近似状态分布,并且在较小的分箱窗口下经历了 $R^2$ 分数的显著下降。尽管如此,rEFH 和 ANN 模型的趋势线表明,rEFH 可以实现比 ANN 更好的延迟与保真度权衡。这源于 ANN 需要大量的分箱窗口历史来提取时间信息,从而导致高延迟。对于 ANN,减少分箱窗口的数量会导致保真度显著下降。浅层 LSTM 实现了比传统解码器和 ANN 更低的延迟与保真度权衡,如趋势线所示,实现了超过 60% 的峰值 $R^2$ 分数,同时延迟介于 4.05 毫秒和 16.05 毫秒之间。值得注意的是,使用 16 毫秒的较长分箱窗口时,保真度显著下降,这表明 LSTM 依赖于神经数据的时间维度来提取有关神经动态的信息。SNN 在所有三个模型中都实现了具有竞争力的 $R^2$ 分数和更低延迟的最佳权衡。随着层数的增加,延迟仅略有增加。
The overall trend of the six decoders shows that recurrent neural networks (RNNs), such as the SNN and the LSTM, can achieve competitive fidelity to non-recurrent ones while extracting neural dynamics from intra-cortical spike data and having significantly lower latency, with SNNs maintaining lower latency for higher fidelity than LSTMs.
整体趋势显示,递归神经网络 (RNN),如 SNN 和 LSTM,可以实现与非递归网络相当的保真度,同时从皮层内脉冲数据中提取神经动态,并具有显著较低的延迟,SNN 在较高保真度下保持比 LSTM 更低的延迟。
Power consumption vs. fidelity
MACs, reported as the number of inner products of matrix-vector multiplications, are indifferent to the length of the vectors in the inner product. This makes them inadequate for assessing power consumption. Instead, the total number of required operations during inference provides a better estimate of the actual energy cost. Figure 7 shows the operational cost versus fidelity tradeoff of the neural decoders.
MAC 作为矩阵-向量乘法的内积次数进行报告,对内积中向量的长度无动于衷。这使得它们不适合评估功耗。相反,推理过程中所需的总操作数提供了对实际能量成本的更好估计。图 7 显示了神经解码器的操作成本与保真度权衡。
Visualized trade-off between $R^2$ score and total operations. The specific closed-loop setting requires neural decoders in the bottom right corner. ANN-based decoders, such as the ANN and the LSTM depicted as triangles, are an improvement compared to traditional decoders, represented as squares. Yet, the SNN, denoted by circles, achieves the lowest operational cost while maintaining competitive $R^2$ scores. Comparing memory access instead of total operations shows the same trend and is redundant.
$R^2$ 分数与总操作数之间的权衡可视化。特定的闭环设置需要位于右下角的神经解码器。基于 ANN 的解码器(如图中的 ANN 和 LSTM,表示为三角形)相比传统解码器(表示为方块)有所改进。然而,SNN(表示为圆圈)在保持竞争力的 $R^2$ 分数的同时实现了最低的操作成本。比较内存访问而不是总操作数显示了相同的趋势,因此是多余的。
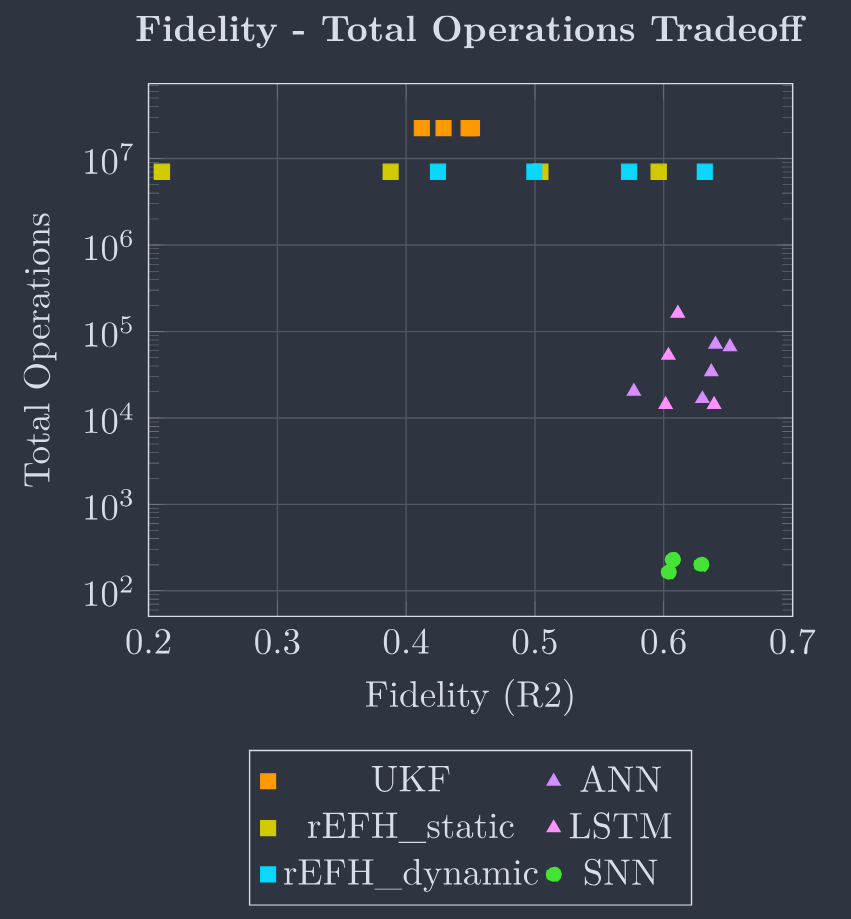
All traditional decoders require matrix operations with large inner products, leading to, by far, the most operations to effectively decode neural signals. The average number of operations for traditional decoders across the experiments was between 700 000 and 2300 000. The three decoders have the same high number of total operations across the various binning windows because unlike the other models, the length of the binning window does not affect the operational cost. Traditional decoders had the most extensive range of $R^2$ scores, ranging from 23% to 66%. NN-based decoders represent a shift towards more computationally efficient decoding algorithms. Our experiments demonstrated significantly reduced power consumption compared to traditional decoders. The LSTM with 16 hidden neurons required 4700 operations, whereas the ANN with seven binned windows required approximately 34 000 operations. Compared to the traditional decoders, this significant improvement comes with consistently high fidelity, with $R^2$ values of ANN-based decoders ranging from 50% to 65%. The SNN decoders exhibited the highest energy efficacy among the decoder types considered in this study. On average, SNN decoders required 200 operations while achieving competitive fidelity levels, with $R^2$ values ranging from 60% to 63%.
所有传统解码器都需要具有大内积的矩阵操作,从而导致迄今为止解码神经信号所需的操作最多。传统解码器在实验中的平均操作次数在 700,000 到 2,300,000 之间。这三种解码器在各种分箱窗口中具有相同的高总操作数,因为与其他模型不同,分箱窗口的长度不会影响操作成本。传统解码器具有最广泛的 $R^2$ 分数范围,范围从 23% 到 66%。基于 NN 的解码器代表了向更高效计算解码算法的转变。我们的实验表明,与传统解码器相比,功耗显著降低。具有 16 个隐藏神经元的 LSTM 需要 4700 次操作,而具有七个分箱窗口的 ANN 大约需要 34,000 次操作。与传统解码器相比,这一显著改进伴随着始终如一的高保真度,基于 ANN 的解码器的 $R^2$ 值范围从 50% 到 65%。SNN 解码器在本研究考虑的解码器类型中表现出最高的能量效率。SNN 解码器平均需要 200 次操作,同时实现具有竞争力的保真度水平,$R^2$ 值范围从 60% 到 63%。
Comparing memory access instead of total effective operations reveals the same tradeoff and is not reiterated. A comparison of the power consumption and fidelity metrics reveals an intriguing trade-off among the three decoder types. While traditional decoders require substantial operations, they offer a range of $R^2$ scores. In contrast, ANN-based and SNN-based decoders provide the advantage of reduced energy costs, with SNN decoders exhibiting the lowest computational load while maintaining competitive fidelity levels.
比较内存访问而不是总有效操作揭示了相同的权衡,并未重申。功耗和保真度指标的比较揭示了三种解码器类型之间有趣的权衡。虽然传统解码器需要大量操作,但它们提供了一系列 $R^2$ 分数。相比之下,基于 ANN 和 SNN 的解码器提供了降低能量成本的优势,SNN 解码器在保持竞争力的保真度水平的同时表现出最低的计算负载。
Bayesian information criterion (BIC)
The BIC serves as a valuable instrument for the comparing various neural networks, effectively addressing the concern of increased model complexity and its potential impact on performance enhancement. The BIC introduces a penalization term for the number of model parameters, thereby discouraging the adoption of overly complex models with excessive weights and biases. This penalty term effectively balances fidelity and model complexity, enabling us to discern whether a model’s performance improvements stem from an increased number of learnable parameters or architectural design.
BIC 是比较各种神经网络的有价值的工具,有效地解决了模型复杂性增加及其对性能提升的潜在影响的问题。BIC 为模型参数的数量引入了惩罚项,从而阻止采用具有过多权重和偏置的过于复杂的模型。该惩罚项有效地平衡了保真度和模型复杂性,使我们能够辨别模型的性能改进是源于可学习参数数量的增加还是架构设计。
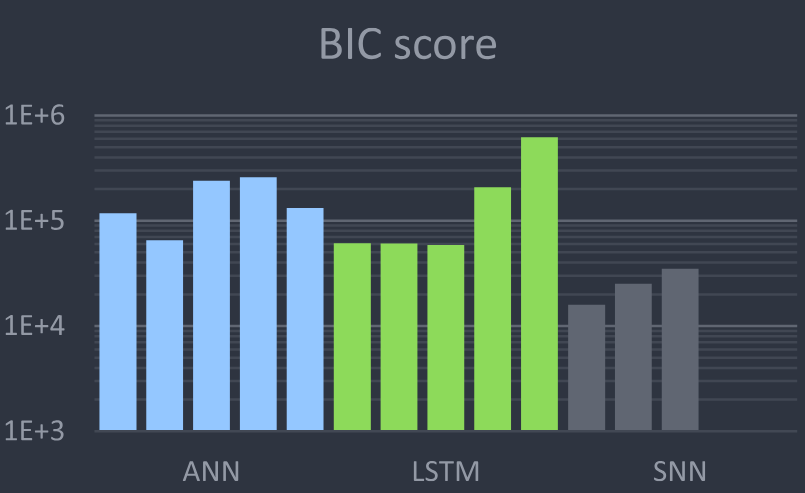
Figure 8 presents the BIC values for various configurations of the three neural network-based decoders. Notably, the single-layer SNN, characterized by its minimal complexity, attains the lowest BIC score. In contrast, SNN2 and SNN3 had significantly higher BIC scores despite exhibiting performance improvements. This discrepancy suggests that the performance improvements are disproportional to the increased number of learnable parameters in these models. All SNNs achieved much lower BIC scores than the traditional and ANN-based neural decoder.
图 8 展示了三种基于神经网络的解码器的各种配置的 BIC 值。值得注意的是,单层 SNN 以其最小的复杂性获得了最低的 BIC 分数。相比之下,尽管 SNN2 和 SNN3 表现出性能提升,但它们的 BIC 分数显著更高。这种差异表明,这些模型中的性能改进与可学习参数数量的增加不成比例。所有 SNN 的 BIC 分数都远低于传统和基于 ANN 的神经解码器。
The evaluated NN-based decoders’ Bayesian information criterion (BIC) shows that the SNN achieve far lower BIC scores than other decoders, suggesting that SNNs are more suitable for the constrained closed-loop setting. A low BIC indicates that a decoder can learn better, given its complexity. The lowest BIC score is achieved by SNN1. The various models appear in the same order as presented in table 2.
评估的基于 NN 的解码器的贝叶斯信息准则 (BIC) 显示,SNN 实现了远低于其他解码器的 BIC 分数,这表明 SNN 更适合受限的闭环设置。较低的 BIC 表明,给定其复杂性,解码器可以学习得更好。最低的 BIC 分数由 SNN1 实现。各种模型的出现顺序与表 2 中呈现的顺序相同。
Discussions
In conclusion, optimizing neural decoders for closed-loop iBCI systems capable of CLN presents a delicate balance, requiring careful consideration of the trade-offs between fidelity, latency, power consumption, and memory size. Our findings emphasize that although more complex and deeper neural architectures with more trainable parameters, hold the potential for improved decoding accuracy, optimizing only for fidelity by increasing the complexity of a network can result in reduced usability for closed-loop iBCIs. The decoding accuracy reaffirms the findings of Glaser et al that conventional neural network-based decoders can achieve the highest R2 scores. However, we observe that this comes at the cost of increased latency and power consumption. Even when only considering fidelity, evaluating the BIC across the three NN-based decoders showed that SNNs consistently outperformed the ANN and the LSTM, achieving significantly lower BIC scores. This indicates that the performance improvement of the ANN is due to disproportionally more learnable parameters. Remarkably, the single-layer SNN emerged as the top performer out of the models we benchmarked in this paper, signifying its suitability for effectively learning data variance, particularly when considering the number of learnable parameters. This highlights that the shallow SNN is preferable for robust and energy-efficient neural decoding, given its complexity among the three neural network-based decoder types we evaluated.
总之,为能够实现 CLN 的闭环 iBCI 系统优化神经解码器需要在保真度、延迟、功耗和内存大小之间进行微妙的平衡。我们的研究结果强调,尽管具有更多可训练参数的更复杂和更深的神经架构具有提高解码准确性的潜力,但仅通过增加网络的复杂性来优化保真度可能会降低闭环 iBCI 的可用性。解码准确性重申了 Glaser 等人的发现,即传统的基于神经网络的解码器可以实现最高的 $R^2$ 分数。然而,我们观察到,这以增加延迟和功耗为代价。即使仅考虑保真度,评估三种基于 NN 的解码器的 BIC 也显示 SNN 始终优于 ANN 和 LSTM,实现了显著较低的 BIC 分数。这表明 ANN 的性能提升是由于不成比例地更多的可学习参数。值得注意的是,单层 SNN 成为我们在本文中基准测试的模型中的最佳表现者,表明其适合有效学习数据方差,特别是考虑到可学习参数的数量。这突显出,在我们评估的三种基于神经网络的解码器类型中,考虑到其复杂性,浅层 SNN 更适合进行稳健且节能的神经解码。
The ability of a neural decoder to effectively harness sparsity represents a crucial design consideration in closed-loop iBCI systems. Conventional neural data are characterized by their inherent sparsity and temporal encoding, with rate-based encoding accounting for a mere fraction of the neural activity in regions such as the visual cortex. The inherent sparsity of neural spikes provides SNNs with a distinct advantage, enabling them to capitalize on the spatiotemporal structure of the input data, which is less pronounced in non-neuromorphic ANNs.
神经解码器有效利用稀疏性的能力是闭环 iBCI 系统中的一个关键设计考虑因素。传统的神经数据以其固有的稀疏性和时间编码为特征,基于速率的编码仅占视觉皮层等区域神经活动的一小部分。神经脉冲的固有稀疏性为 SNN 提供了独特的优势,使其能够利用输入数据的时空结构,而这种结构在非神经形态的 ANN 中不那么明显。
SNNs have previously demonstrated their potential for reduced power consumption and lower latency in various applications. In our study, we reaffirm and extend these prior findings, indicating that SNNs can extract neural dynamics from extracellular spiking data, while maintaining competitive fidelity and showing superior performance in terms of power consumption and latency.
SNN 先前已展示了其在各种应用中降低功耗和延迟的潜力。在我们的研究中,我们重申并扩展了这些先前的发现,表明 SNN 可以从细胞外脉冲数据中提取神经动态,同时保持竞争力的保真度,并在功耗和延迟方面表现出卓越的性能。
The latency metric introduced in our analysis operates under the assumption that the computation of an inner product is equivalent to a single addition in terms of clock cycles. Although this abstraction aligns with standard practices for MAC operations, it is essential to acknowledge that this assumption may only partially represent the potential hardware optimizations for vector accumulations. While the process of counting additions might initially appear as a potential disadvantage when comparing SNNs to ANNs in the context of latency, we observe that despite this methodological abstraction, SNNs consistently achieved substantially lower latency when compared to traditional decoders and the ANN. The longer latency of traditional decoders and ANNs is primarily attributed to their reliance on long binning windows for extracting temporal information and their high operational cost. Notably, the sole exception to this trend is the LSTM, which demonstrates a latency level comparable to that of SNNs. This observation reaffirms the findings of Zenke et al, who demonstrated the efficiency of RNNs, such as LSTMs and SNNs, in exploiting the temporal structure of neural data, emphasizing their capacity to achieve competitive fidelity with low latency in a closed-loop neural decoding system. These insights underscore that even without accounting for the potential hardware optimizations, SNNs can exhibit a marked advantage in terms of latency over traditional decoder models and non-recurrent ANNs, which require more extensive computational resources owing to their temporal information extraction procedures.
我们分析中引入的延迟指标假设内积的计算在时钟周期方面等同于单次加法。尽管这种抽象与 MAC 操作的标准做法一致,但必须承认,这一假设可能仅部分代表了向量累积的潜在硬件优化。虽然在延迟方面比较 SNN 和 ANN 时,计算加法的过程最初似乎是一个潜在的劣势,但我们观察到,尽管存在这种方法论抽象,SNN 与传统解码器和 ANN 相比仍始终实现了显著较低的延迟。传统解码器和 ANN 较长的延迟主要归因于它们依赖于长分箱窗口来提取时间信息及其高操作成本。值得注意的是,这一趋势的唯一例外是 LSTM,其显示出与 SNN 相当的延迟水平。这一观察结果重申了 Zenke 等人的发现,他们展示了 RNN(如 LSTM 和 SNN)在利用神经数据的时间结构方面的效率,强调了它们在闭环神经解码系统中以低延迟实现竞争力保真度的能力。这些见解强调,即使不考虑潜在的硬件优化,SNN 在延迟方面也能表现出明显优于传统解码器模型和非递归 ANN 的优势,后者由于其时间信息提取程序而需要更多的计算资源。
The advantages of employing neuromorphic SNNs for closed-loop iBCIs become more apparent when the energy cost is evaluated using the total number of operations. In this context, SNNs significantly outperform traditional and ANN-based decoders. Our results show that traditional and ANN-based decoders require several orders of magnitude more operations to attain performance levels comparable to SNNs. The remarkable reduction in the number of operations required by SNNs can be attributed to their constrained design, which minimizes the number of learnable parameters while still delivering competitive performance. However, the primary driving forces behind the substantially lower energy cost associated with SNNs lies in their ability to exploit sparsity and their more energy-efficient operations. This capacity allows for approximately 5% of the operations to be executed, emphasizing the exceptional efficiency achieved by SNNs while maintaining high fidelity. Following previously reported estimates of required energy per operation, we observe an approximate energy cost of around $2 \mu\text{W}$ per inference for the SNNs, which is 50 times lower than for the LSTM, 100 times lower for the ANN, and 10 000 times lower than for the UKF.
采用神经形态 SNN 用于闭环 iBCI 的优势在使用总操作数评估能量成本时变得更加明显。在这种情况下,SNN 显著优于传统和基于 ANN 的解码器。我们的结果显示,传统和基于 ANN 的解码器需要多个数量级的更多操作才能达到与 SNN 相当的性能水平。SNN 所需操作数的显著减少可归因于其受限的设计,该设计在最小化可学习参数数量的同时仍提供竞争力的性能。然而,与 SNN 相关的显著较低能量成本的主要驱动力在于它们利用稀疏性和更节能操作的能力。这种能力使得大约 5% 的操作得以执行,强调了 SNN 在保持高保真度的同时实现的卓越效率。根据先前报告的每次操作所需能量的估计,我们观察到 SNN 每次推理的大约能量成本约为 $2 \mu\text{W}$,这比 LSTM 低 50 倍,比 ANN 低 100 倍,比 UKF 低 10,000 倍。
The field of neurotechnology and BCIs are rapidly expanding. New advancements and technologies enable the development of more effective, user-friendly, and versatile BCIs. This paper discusses two main challenges in designing processors for implantable closed-loop neural decoders: low energy consumption to minimize heat diffusion, and low latency to enable real-time CLN. We defined metrics for neural decoders and benchmarked common decoding methods to predict a primate’s finger kinematics. This study explores the suitability of low latency and low computing neural decoders and highlights the potential advantages of neuromorphic SNNs for CLN. Our results show that SNNs can balance decoding accuracy and operational efficiency, offering immense potential for reshaping the landscape of neural decoders and opening new frontiers in closed-loop intracortical human-brain interaction.
神经技术和 BCI 领域正在迅速扩展。新的进展和技术使得开发更有效、用户友好且多功能的 BCI 成为可能。本文讨论了为可植入闭环神经解码器设计处理器的两个主要挑战:低能耗以最小化热扩散,以及低延迟以实现实时 CLN。我们为神经解码器定义了指标,并基准测试了常见的解码方法以预测灵长类动物的手指运动学。本研究探讨了低延迟和低计算神经解码器的适用性,并强调了神经形态 SNN 在 CLN 中的潜在优势。我们的结果表明,SNN 可以平衡解码准确性和操作效率,为重塑神经解码器的格局提供了巨大的潜力,并为闭环皮层内人脑交互开辟了新的前沿。
Using neuromorphic SNNs for CLN is an area of research with great promise, as indicated by successfully predicting an NHP finger kinematic in this study. However, the list of evaluated decoders is non-exhaustive, and only a single neural decoder, the SNN, was optimized for latency and power consumption. This allows for comparing commonly used decoders, yet it favors inherently efficient and fast neuromorphic decoders. Additionally, only one exemplary dataset was evaluated as representative of closed-loop iBCI tasks requiring low latency and power consumption. Therefore, this study highlights the potential of SNN for iBCI for CLN, however, further studies are required to explore the suitability of these networks for other types of neural decoding tasks and to optimize their performance to meet the requirements of CLN systems. Developing fully implantable iBCIs with local processing capabilities is crucial for reducing energy consumption and latency and improving the real-time applicability of CLN systems.
在本研究中成功预测 NHP 手指运动学表明,使用神经形态 SNN 进行 CLN 是一个充满希望的研究领域。然而,评估的解码器列表并不详尽,只有单个神经解码器 SNN 针对延迟和功耗进行了优化。这允许比较常用的解码器,但有利于本质上高效且快速的神经形态解码器。此外,仅评估了一个典型数据集,作为需要低延迟和功耗的闭环 iBCI 任务的代表。因此,本研究突显了 SNN 在 CLN iBCI 中的潜力,但需要进一步的研究来探索这些网络在其他类型神经解码任务中的适用性,并优化其性能以满足 CLN 系统的要求。开发具有本地处理能力的完全可植入 iBCI 对于降低能耗和延迟以及提高 CLN 系统的实时适用性至关重要。
Overall, the outlook for neural engineering and BCIs is bright. New developments will improve neural recording and decoding technologies, ultimately enhancing our understanding of the brain and its complex neural processes.
总体而言,神经工程和 BCI 的前景光明。新的发展将改善神经记录和解码技术,最终增强我们对大脑及其复杂神经过程的理解。
Conclusion
Our study introduces methods to extrapolate algorithmic-to-hardware metrics that allow evaluating the low latency and high energy efficacy requirements of iBCI suitable for CLN. We present six commonly used neural decoders and compare them in predicting an NHP fine motor kinematics from binned neural activity. Our results highlight the potential advantages of neuromorphic SNNs in the context of iBCIs capable of CLN. In our benchmark, we observe that SNNs outperform other commonly used decoders, with evident performance differences when compared against benchmarked traditional decoders. Notably, the exceptionally low latency of SNNs and LSTMs, surpassing that of traditional decoders and non-RNNs, arises from their innate ability to extract temporal information from spiking neural data. The power efficiency can be attributed to the adeptness of SNNs in exploiting sparsity and their deliberately constrained architectural design. Our results show that SNNs can achieve competitive decoding performance in less than 5 ms, using less than 1% of computational resources, and more than 50 times less energy than other neural decoding methods in this benchmark. This makes them highly suitable candidates for closed-loop iBCI challenges and positions them as a game-changing technology for reshaping the landscape of neural decoders. Significant advancements in CLN can be achieved by adopting SNNs as the preferred neural decoder. Their capacity for efficient and accurate neural signal processing holds the potential to revolutionize BCI applications, enhancing our ability to interact with and understand the intricacies of the human brain.
我们的研究引入了将算法指标外推到硬件指标的方法,使得评估适用于 CLN 的 iBCI 的低延迟和高能效要求成为可能。我们展示了六种常用的神经解码器,并比较了它们在根据分箱神经活动预测 NHP 精细运动学方面的表现。我们的结果突显了神经形态 SNN 在能够实现 CLN 的 iBCI 背景下的潜在优势。在我们的基准测试中,我们观察到 SNN 优于其他常用解码器,与基准传统解码器相比表现出明显的性能差异。值得注意的是,SNN 和 LSTM 的异常低延迟超过了传统解码器和非 RNN,这源于它们从脉冲神经数据中提取时间信息的天生能力。功率效率可归因于 SNN 在利用稀疏性方面的熟练程度及其有意受限的架构设计。我们的结果表明,SNN 可以在不到 5 毫秒内实现具有竞争力的解码性能,使用不到 1% 的计算资源,并且比本基准中的其他神经解码方法节省超过 50 倍的能量。这使得它们成为闭环 iBCI 挑战的高度合适候选者,并将其定位为重塑神经解码器格局的变革性技术。通过采用 SNN 作为首选神经解码器,可以在 CLN 方面取得重大进展。它们高效且准确处理神经信号的能力有望彻底改变 BCI 应用,增强我们与人类大脑复杂性互动和理解的能力。