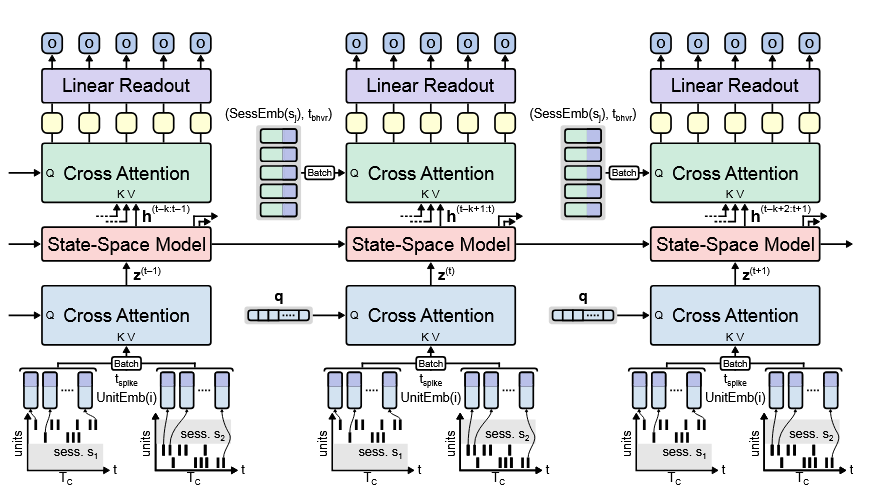
数据流解析.
- 预处理后数据
dataset的结构为self.dataset = [trial_0, trial_1, ...], 每个元素形式是
trial = {
'trial_id': trial_id, # 单次实验的编号
'spikes': active_spike, # 动作电位数据
'vel': vel # 速度
}
-
active_spike = List[bin],bin = List[(channel_id, offset),...]或者0. -
vel = List[vel_bin],vel_bin = List[(v_x, v_y)...].
- 通过
Dataloader.py将dataset转化为 tensor.pad_collate_fn输出了padded_bin, bin_mask, spike_mask, vel.
padded_bin: (batch,max_bin,max_token,2) 的张量,2来自于 token(channel_id, offset).
batch: 每次训练的批量大小;max_bin: 一个 batch 中最长的 bin 的长度;max_token: 一个 bin 中最多的 token 的数量.
-
bin_mask: (batch,max_bin) 的 bool 张量, 标记哪些 bin 是真实有效而非填充为0的. -
spike_mask: (batch,max_bin,max_token) 的 bool 张量, 标记哪些 token 是真实有效的而非填充为0的.
possm_model.py进行 Embedding 语义升维.
Dataloader.py 输出的 spike (即 padded_bin) 为 (batch, max_bin, max_token, 2), 经过
channels, offsets = spike[..., 0], spike[..., 1]
拆分为 (batch, max_bin, max_token) 的 channels 和 offsets.
self.emb = nn.Embedding(
num_embeddings = config.num_channel,
embedding_dim = config.embed_dim
)
通过 emb = self.emb(channels) 将 (batch, max_bin, max_token) 的 channels 转化为 (batch, max_bin, max_token, embed_dim) 的 emb.
embed_dim: 用于将 1 个channel_id升维为embed_dim维的矢量.
cross_attention.py将emb转换为num_latents个 latent 向量.
emb: (batch_size,max_bin,max_token,embed_dim)offsets: (batch_size,max_bin,max_token) 的张量, 包含每个 token 的 bin 内相对时间.spike_mask: (batch_size,max_bin,max_token) 的 bool 张量, 标记哪些 token 是非填充的
z = self.cross_attention(emb, offsets, spike_mask, self.freqs_cos, self.freqs_sin)
z: (batch_size,max_bin,num_latents,embed_dim) 的张量
latents = self.latent_query
xq = self.q_proj(latents).unsqueeze(0).unsqueeze(0).expand(batch_size, max_bin, -1, -1)
latents: 随机初始化的 (num_latents,embed_dim) 张量xq: (batch_size,max_bin,num_latents,num_attention_heads*head_dim)
self.q_proj(latents) 通过 linear layer 将 latents 升维为 Query 向量 (num_latents, num_attention_heads * head_dim),
再通过 .unsqueeze(0).unsqueeze(0).expand(batch_size, max_bin, -1, -1) 扩展为 xq.
xk = self.k_proj(spike)
xv = self.v_proj(spike)
xk: (batch_size,max_bin,max_token,num_key_value_heads*head_dim) spike 通过 linear layer 升维为 Key 向量xv: (batch_size,max_bin,max_token,num_key_value_heads*head_dim) spike 通过 linear layer 升维为 Value 向量
因此这里实际上是 self attention.
xq = xq.view(batch_size, max_bin, self.num_latents, self.n_local_heads, self.head_dim)
xk = xk.view(batch_size, max_bin, max_token, self.n_local_kv_heads, self.head_dim)
xv = xv.view(batch_size, max_bin, max_token, self.n_local_kv_heads, self.head_dim)
# self.n_local_heads = num_attention_heads
# self.n_local_kv_heads = num_key_value_heads
对 xq, xk, xv 进行 reshape. 其中
xk = RotaryEmbedding.apply_rotary_pos_emb(xq, xk, cos, sin, offsets, is_decoder=False)
对 xk 应用 Rotary Positional Embedding, offsets 是每个 token 在 bin 内的相对时间.
# 4. Transpose for Attention
xq = xq.transpose(2, 3) # 调换第 3 和 第 4 维
xk = repeat_kv(xk, self.n_rep).transpose(2, 3)
xv = repeat_kv(xv, self.n_rep).transpose(2, 3)
为注意力计算做准备.
xq: (batch_size,max_bin,num_latents,num_attention_heads,head_dim) -> (batch_size,max_bin,num_attention_heads,num_latents,head_dim)
通过 repeat_kv() 将 xk 和 xv 的 num_key_value_heads 维度扩展为 num_attention_heads 维: (batch_size, max_bin, max_token, num_attention_heads, head_dim),
再通过 .transpose(2, 3): (batch_size, max_bin, num_attention_heads, max_token, head_dim)
注意力机制公式 $\text{Attention}(Q,K,V) = \text{softmax}(\frac{QK^{\dagger}}{\sqrt{d_{k}}})V$
# 5. Calculate Attention
scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(self.head_dim)
xq @ xk.transpose(-2, -1): 对最后两个维度进行矩阵乘法, 即
scores: (..., num_latents, head_dim) @ (..., head_dim, max_token) -> (batch_size, max_bin, num_attention_heads, num_latents, max_token)
# Apply mask if provided
mask = mask_spike.unsqueeze(2).unsqueeze(2)
scores = scores.masked_fill(mask == False, float('-inf'))
mask: mask_spike (batch_size, max_bin, max_token) 通过 .unsqueeze(2).unsqueeze(2) 展开为 (batch_size, max_bin, 1, 1, max_token)
scores 中的填充 0 位使用 float('-inf'), 以确保 softmax 后这些位置的权重为 0.
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
scores: (batch_size, max_bin, num_attention_heads, num_latents, max_token)
output = scores @ xv
output: (..., num_latents, max_token) @ (..., max_token, head_dim) -> (batch_size, max_bin, num_attention_heads, num_latents, head_dim), 这样就消除了因数据而异的 max_token 而得到定长.

